As generative AI models advance, it is becoming increasingly common for models to be multimodal, or able to process multiple data types (text, image, video, audio, etc.). To overcome model context limitations and knowledge cutoff dates, we can use RAG to present our multimodal data to the model to enhance generated responses.
Today, we’ll explore creating multimodal vector embeddings and storing them in KDB.AI for efficient retrieval. We’ll then leverage this retrieved data to feed a Large Language Model (LLM) and generate a response based on the user’s query.
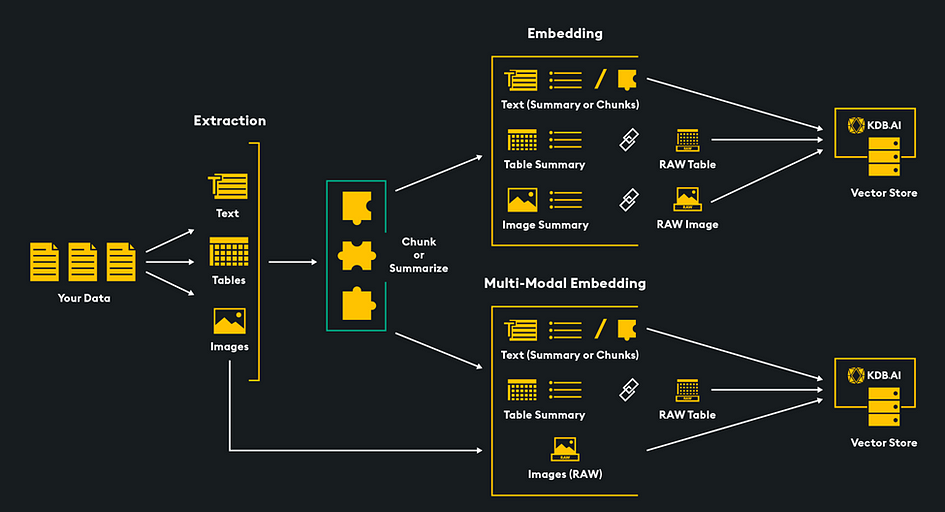
In these samples, we will use the KDB.AI vector database as a multimodal retrieval engine to power a RAG pipeline. Both images and text will be embedded, stored, retrieved, and used to augment an LLM and generate a response for the user. Let’s dive into two methods to create this RAG pipeline: