Large Language Models (LLMs) have taken the world by storm over the past few years due to their ability to understand and generate human-like text. These models come in various forms including: Autoencoder-Based, Sequence-to-Sequence, Recursive Neural Network, and the most well-known, Transformer-Based Models. Each has their own strengths and weaknesses for different tasks, but Transformer-Based LLMs have proven to be some of the most versatile. So, how do they work?
Transformer-Based LLMs
Let’s start with a sentence: “Neil wants his bank to cash the check”
Does “bank” refer to a river, a tilting aircraft, or a financial institution? Is “cash” a noun as in the paper form of money, or is it a verb as in the action of transferring paper money? Is “check” a chess move, someone examining something, or a paper note for money?
You likely had no issue discerning all this when reading the initial sentence. That is because humans are very good at understanding context. Machines do this with transformers.
Transformers are deep neural networks that work to encode data (like words) into vector embeddings that they can understand, manipulate, and then eventually decode back into new words for you to understand. In practice, there are multiple layers of transformers that pass embeddings progressively until the final output of meaningful results are used to predict the next word in a sequence. In these layered transformers, outputs of one transformer become the inputs for the next transformer, and the context builds up, much like the following simplified diagram:
Here, we start with our original sentence. The first transformer contextualizes that some words are used as nouns and verbs. The second transformer contextualizes pronouns, who they belong to, and other references like “bank” being a financial institution. This can progress through dozens of transformer layers with each word carrying up to thousands of dimensions about its meaning. For example, GPT-3 carries 12,288 dimensions for each word! As data passes through these transformer layers, the context is built and refined. This is because each layer can use the self-attention mechanism to consider the entire input sequence simultaneously, unlike traditional models that process data sequentially. The goal is for the final layer to carry enough information so that the next word in a sequence can be predicted. This carries on until a stopping prediction is met.
In Transformer-Based LLMs, such as OpenAI’s ChatGPT and Anthropic’s Claude, there are many layers of transformers, pre-trained on text and fine-tuned for chat. The pre-training utilizes massive corpora of text data to learn what words are typically followed by other words. It is then fine-tuned for specific tasks like Text Summarization, Language Generation, or Question-Answering.
Limitations and Considerations
The process of training and fine-tuning an LLM requires considerable expertise, financial resources, and compute time. For example, it’s estimated that GPT-4 took around 100 days and $100 million to train, by the world’s top AI experts. What’s more, these LLMs are frozen in time based on the data they were trained on. They can’t infer new results based on data available after their training date or data outside their training set. For example, as of writing this article, ChatGPT only had data available up to September 2021:
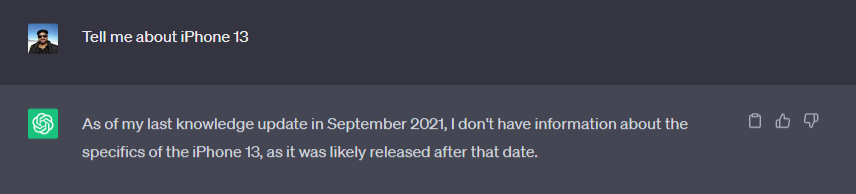
Given these limitations, there is much to be desired from LLMs to make real business impact. This is where Retrieval Augmented Generation (RAG) and vector databases come in. They allow you to utilize the intelligence of existing LLMs but combined with your own knowledge bases. Using a vector database and a few API endpoints, an AI Chatbot with personal knowledge base can be built in as little as 10 minutes for free using KDB.AI and open source LLMs. The rest of this article details the flow of this process through the steps of Data Preprocessing, Prompt Construction, and Prompt Execution.
Data Pre-Processing
First of all, what is your data? Is it structured like CSV, JSON, or SQL Tables? Is it unstructured like documents, video, or images? All can be used through the magic of vector embeddings which are generated by passing your data through embedding model and storing the resulting embeddings in a vector database. There are tons of embedding models available open source to select from, or you can build your own. For example, OpenAI provides text-embedding-ada-002 while HuggingFace lists dozens for download.
Vector databases themselves are considered the most critical piece of data pre-processing. This is your “knowledge base.” KDB.AI, for example, efficiently stores, searches, and retrieves across billions of embeddings in an easy-to-use cloud-hosted or self-managed environment. As opposed to other data storage mechanisms, vector databases offer some of the same benefits as traditional databases such as centralized control, scalability, and security.
The vector database is able to receive embeddings from an embedding model and store them in vector space. Then, for retrieval, Approximate Nearest Neighbors can be used with a variety of search mechanisms to find similar data to your query. The vector database can be queried directly with a “query vector” which simply returns approximate matches, or it can utilize orchestration tools like LangChain that incorporate LLMs for a more human-like conversation. Using the vector database and LLM with orchestration looks like this:
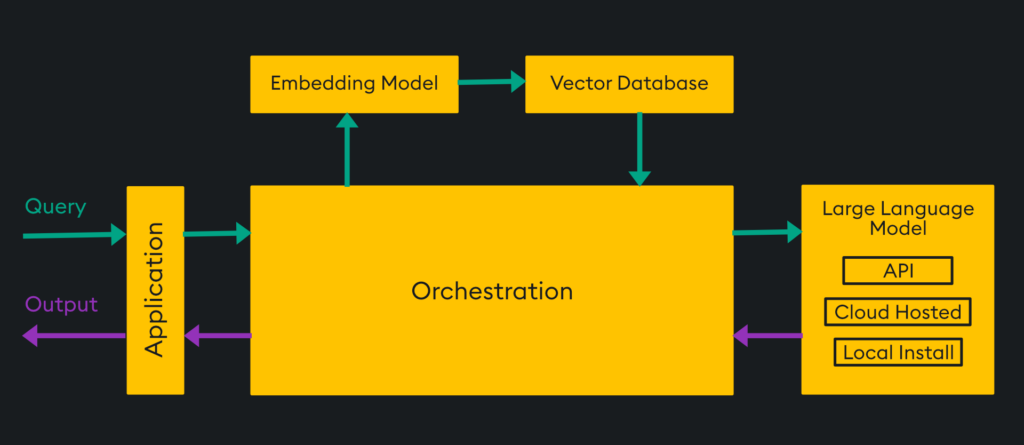
Here, an application is the user interface for a human that provides a query transformed into an embedding, queried in the vector database, combined with a prompt for the LLM, and returned to the user through the application. Let’s discuss how that prompt is generated and how prompting works in general.
Prompt Construction
Modern LLMs have been trained on large amounts of data and fine-tuned with RLHF (reinforcement learning from human feedback), so they can therefore work with zero-shot prompts. That is, prompts with no explicit examples included. In situations where the quality of zero-shot prompt output is poor, an approach called “few-shot” can be employed, in which the prompting individual includes examples of what their expected output is:
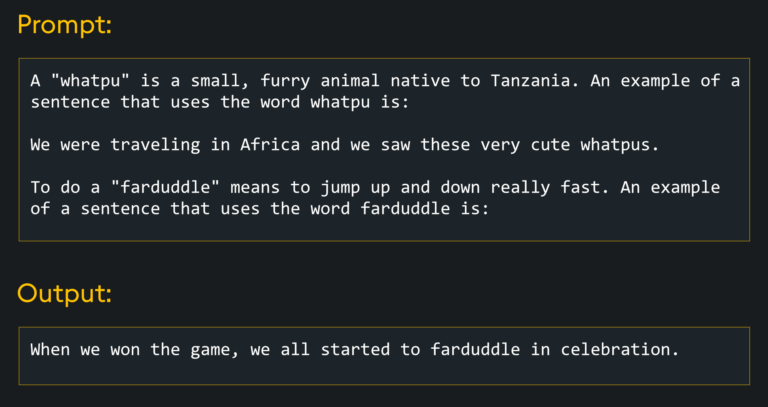
There are other approaches to improving prompts such as Chaining (where the inputs of prompts are chained with the outputs of previous prompts) and Tree of Thought (where the LLM is guided through a reasoning process by the user). In fact, there are many prompting strategies one could employ; we recommend the Prompt Engineering Guide if you want to learn about them.
With RAG, the prompts are constructed by the orchestrator which combines the initial query with related text samples from the vector database (called “chunks”). By taking chunks of context from the vector database and injecting it into a prompt, the LLM has all the necessary information to generate a response even with data outside its training set. If you want to try this, you can use LangChain with your KDB.AI instance via our Sample.
But wait! You may be asking, “Why go through the work of embedding and vector databases? Why not just include all of my documents in the prompt?” This is a good question, and the answer is both 1) token limits, and 2) accuracy degradation. While new LLMs such as Claude 2 boast a 100k token limit, utilizing this token limit is both expensive and still an input length limitation. For instance, Moby Dick has 255k tokens of text and therefore the entire book could not be injected into a prompt. It would be more effective to just use relevant chunks retrieved from a vector database. Furthermore, researchers have shown that accuracy degrades around the middle of the document in longer prompts, meaning you are not getting access to the full knowledge repository you could be by using shorter prompts with only relevant information. For these reasons, vector databases remain a critical component when incorporating your own data.
Prompt Execution
Given a prompt, the LLM processes that input and generates a corresponding response for the user. This prompt could come directly from a user or could be constructed by the orchestrator in the case of RAG. In a RAG pipeline, the orchestrator assembles the prompt by merging the user’s initial input with the most relevant chunks retrieved from a vector database. The LLM can be made available to users through a variety of deployments such as online chat interfaces like ChatGPT, API calls, or self-hosted infrastructure. All of this allows you to harness the high-powered intelligence created during the training and fine-tuning of an LLM without any advanced machine learning knowledge.
There are both proprietary and open source LLMs available, and new ones are released frequently. This space is evolving rapidly and since newer and better models are released at such frequency, this also becomes a reason for not investing time and money fine-tuning any specific LLM unless it’s really needed. But likely, as soon as you’re done fine-tuning, newer models will be released and you may already be outdated.
The hosting of these models can be done through a service-oriented API, a private cloud environment, or even a local installation. With KDB.AI, you can use any of the three. The most common way to access an LLM is through an API, which is required for LLMs like OpenAI’s GPT-4, but other popular LLMs like Meta’s Llama 2 can be downloaded and hosted on a cloud environment with the smaller versions even being deployable on a high-powered laptop. Some newer models like Stanford’s Alpaca 7B are small enough (4GB) to fit on a smartphone or Raspberry Pi. We will likely see models becoming smaller in the near future as the training and fine-tuning processes improve.
Conclusion
In this article we discussed how Transformer-Based LLMs work, the value of Retrieval Augmented Generation, and the broad areas of the multi-component LLM stack: Preprocessing, Prompt Construction, and Prompt Execution. We discussed how you can bring your own data into an LLM and the importance role vector databases play in the stack. If you would like to get started with your own KDB.AI vector database, check out our getting started documentation.