Overview
Large Language Models (LLMs) have a wide range of capabilities and use-cases including text generation, summarization, sentiment analysis, classification, conversational assistant skills, coding/debugging and more. However, even with these capabilities, LLMs lack the knowledge to answer questions about recent events like the weather or news, search the web, or respond to queries on data/databases that the LLM was not trained on. Even mathematics problems are not always straightforward for the LLM to solve, as it can hallucinate an answer rather than solving the problem. This brings us to ask a few questions. How can we give an LLM the capabilities that it currently lacks? Is there a way to add additional skills to the LLM to answer questions that otherwise would not be possible to answer?
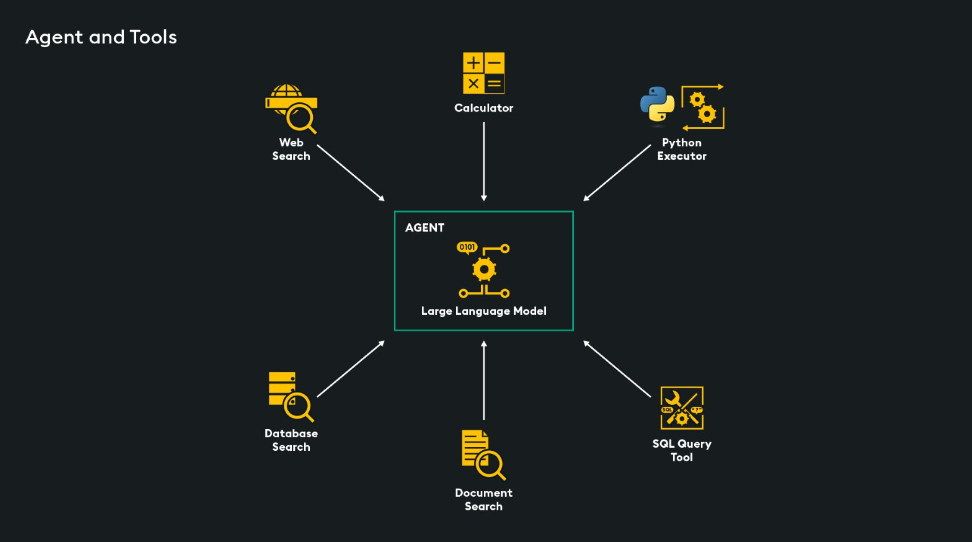
Agents begin to answer these questions. An agent is an LLM powered decision-making engine, it can be thought of as a wrapper around your LLM that will reason what steps must be taken to answer a given user query.
- Agents have access to tools that can be used for specific tasks
- A tool is a function or method that an agent can use to complete a task
- There are many tools that an agent can use, including calculators, code executers, search engines, document search tools, SQL query engines and even custom agents
- When a user sends a query, the agent will decide which tool(s), if any, should be used to answer the user’s question.
The agent controls the interaction between the LLM and available tools.
LangChain Agents
LangChain has several agents that use the ReAct framework, which means they ‘Reason’ the next best steps, and then ‘Act’ by sending the necessary information to the correct tool. The agent can choose to execute multiple steps with the same tool or different tools.
- Zero_Shot_React_Description: This “zero shot” agent type is ideal for performing one-time tasks where we do not need to account for conversational memory or past events. Each new interaction with the agent will be independent, however, within each interaction there can be multiple iterations. For example, a multi-step math problem where the agent would reach out to a calculator tool multiple times.
In this code example, we load a math tool into the ‘zero-shot-react-description’ agent.
from langchain.chains import LLMMathChain
from langchain.agents import Tool
from langchain import OpenAI
from langchain.agents import initialize_agent
from langchain.agents import load_tools
from langchain.agents import AgentType
llm = OpenAI(
openai_api_key="OPENAI_API_KEY",
temperature=0,
model_name="text-davinci-003"
)
llm_math = LLMMathChain(llm=llm)
tools = load_tools(["llm-math"], llm=llm)
agent = initialize_agent{
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True.
max_iterations=5
)
agent.run("what is the answer to: ((3.4*4)+6.2)^4.5")The agent will know to use the calculator tool to answer math questions submitted by the user. However, it will not know what to do if the user asks about another topic. To ensure that our agent-based assistant can handle general questions as well as math questions, we can expose our agent to more tools.
In the below code we will build a custom tool that will call the LLM directly to answer general queries. We will also instantiate a tool called “serpAPI”, which will execute searches and information retrieval on Google. The agent can then choose to call any of the available tools to help answer the user’s query.
from langchain import SerpAPIWrapper
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
#load calculator tool from previous code block
tools = load_tools(["llm-math"], llm=llm)
#serpAPI Google Search tool
search = SerpAPIWrapper(serpapi_api_key='your_api_key')
google_search = [
Tool(
name="serpapi".
func=search.run,
description = "Useful for Google search to find current information"
)
]
#General knowledge direct call to LLM tool
prompt = PromptTemplate(input_variables=["query"], template="{query}")
llm_chain = LLMChain(llm=llm, prompt=prompt)
llm_tool = Tool(name='General Questions for LLM',
func=llm_chain.run,
description='This tool is for querying the LLM for general questions and information')
#Append llm_chain and google_search to our tools list and initialize the agent
tools.append(llm_tool)
tools.append(google_search)
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
max_iteration=5
)
agent.run("What is the longest river in the world?")- Conversational_React_Description: When we need an agent that will be able to remember past interactions and associated information we should use the conversational agent type. This agent type has memory where the chat history can be stored and then referenced:
from langchain.memory import ConversationBufferMemory
#Create chat_history memory
memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
llm = ChatOpenAI(openai_api_key=OPENAI_API_KEY, temperature=0)
agent = initialize_agent(
tools,
llm,
agent=AgentType.CHAT_CONVERSATION_REACT_DESCRIPTION,
verbose=True,
max_interations=5,
memory=memory,
)- React_DocStore: There are certain instances when we need to search external data, the react_docstore agent type will enable interaction with a document store. An example of a document store is Wikipedia. There are two tools to use with the docstore agent, a search tool to bring up the relevant article, and a lookup tool to find the relevant information within the article. Let’s look at an example from LangChain to understand this:
from langchain.docstore import Wikipedia
from langchain.agents.react.base import DocstoreExplorer
docstore = DocstoreExplorer(Wikipedia())
tools = [
Tool(
name="Search",
func=docstore.search,
description="useful for when you need to ask with search",
),
Tool(
name="Lookup",
func=docstore.lookup,
description="useful for when you need to ask with lookup",
),
]
agent = initialize_agent(
tools,
llm,
agent=AgentType.REACT_DOCSTORE,
verbose=True,
max_iterations = 5
)- Self_Ask_With_Search: This agent type is specialized for searching and extracting information from a search engine, for example Google search with serpAPI. The strength is its ability to glean intermediate information to serve finding the final answer. An example of this would be the query:
“Who scored more touchdowns in 2022: Travis Kelce or Davante Adams?”
In this case the agent would decide to search separately how many touchdowns each player had, and then compare the two totals to find who had more. Below is some example code from LangChain:
search = serpAPIWrapper()
#Define tool that will run a Google Search
tools = [
Tool(
name="Intermediate Answer",
func=search.run,
description="useful for when you need to get information from a Google search",
)
]
#Initialize agent with self ask agent type
agent = initialize_agent(
tools,
llm,
agent=AgentType.SELF_ASK_WITH_SEARCH,
verbose=True,
max_iterations = 5
)If you’re curious, a list of LangChain’s available tools is available in their documentation.
Agent Assisted Retrieval Augmented Generation (RAG)
RAG is a method enabling an LLM to answer queries about data that it has not been trained on, like enterprise data. That data is chunked up, embedded, and stored in a vector database. Depending on the user’s query, relevant chunks are retrieved and used to provide context for the LLM’s response.
However, if the query isn’t related to the stored data, it wouldn’t be effective to use the RAG pipeline. In such cases, an agent can determine the next steps, either by using another tool or sending the query directly to the LLM.
We can think of RAG as another tool in the agent’s toolkit – we just need to build that tool and make it available to the agent. This way, depending on the query, the agent can decide whether to use RAG or a different tool.
#Vector Databases loaded w/ embeddings
vecdb_kdbai = KDBAI.from_texts(
session, "rag_langchain", texts=pages, embedding=embeddings
)
#Define RAG chain using kdb.ai vector db as a retriever, w/ top k=10
K=10
qabot = RetrievalQA.from_chain_type(
chain_type="stuff",
llm=ChatOpenAI(model="gpt-3.5-turbo-16k", temperature=0.0),
retriever=vecdb_kdbai.as_retriever(search_kwargs=dict(k=K)),
return_source_documents=True,
)
#Make qabot into a tool to be made available to the agent
tools = [
Tool(
name='Knowledge Base',
func=qabot.run,
description=(
'use this tool when answering queries on Topic xyz '
'more information about the topic xyz'
)
)
]Hugging Face Transformer Agents
Hugging Face is an AI platform with an open-source community for building, training, and deploying machine learning models. It offers ‘Transformer Agents,’ similar to LangChain’s agents, allowing users to leverage various transformer models from the Hugging Face community. This enables dynamic selection of tools based on the user’s query without pre-defining them.
Available transformer models include image generation, image question answering, image segmentation, image, captioning, document question answering, text classification, text summarization, translation, speech-to-text and text-to-speech.
The transformer agent uses an LLM to decide which transformer model to use based on the user’s query, it then downloads the corresponding transformer model, runs the task, and returns the output to the user.
In this example, we use an ‘OpenAiAgent’ running gpt-3 as our LLM powered agent to decide what transformer model to use based on an input prompt. We could also set this up with an open-source LLM agent from Hugging Face or use a local LLM.
from transformers import OpenAiAgent
#define the agent with gpt-3
agent = OpenAiAgent(model="text-davinci-003", api_key="<your_api_key>")
#generate an image based on a description
cat_boat_image = agent.run("generate an image of a cat in a boat on the water")
#Transform the image
cat_dog_boat_image = agent.run("Transform the image in 'picture' to add a dog next to the cat", picture=cat_boat_image)
#caption the transformed image
caption = agent.run("Caption the image in 'picture'",
picture = cat_dog_boat_image)Multi-Agent Framework: AutoGen
AutoGen is a multi-agent conversational framework by Microsoft that allows developers to create and customize agents with specialized roles. These conversable agents can exchange information and collaborate autonomously to complete tasks, enabling developers to set up a group of agents and let them collectively work towards a solution. There are two main classes of agents:
- UserProxyAgent: a proxy agent for a human. It acts as the human in the loop, it is responsible for next step decision making. The agent can solicit feedback from a human, or automatically formulate a reply at each interaction. It also can execute code and call functions.
- AssistantAgent: acts as an AI assistant. It does not require human input or code execution. It uses an underlying LLM to complete its tasks. An example is it can write code (using the LLM) when a task is received. It can also receive and interpret execution results and debug errors or suggest improvements.
To conceptualize how these two types of agents work together, let us take an example where there is a simple two agent setup with one UserProxyAgent and one AssistantAgent.
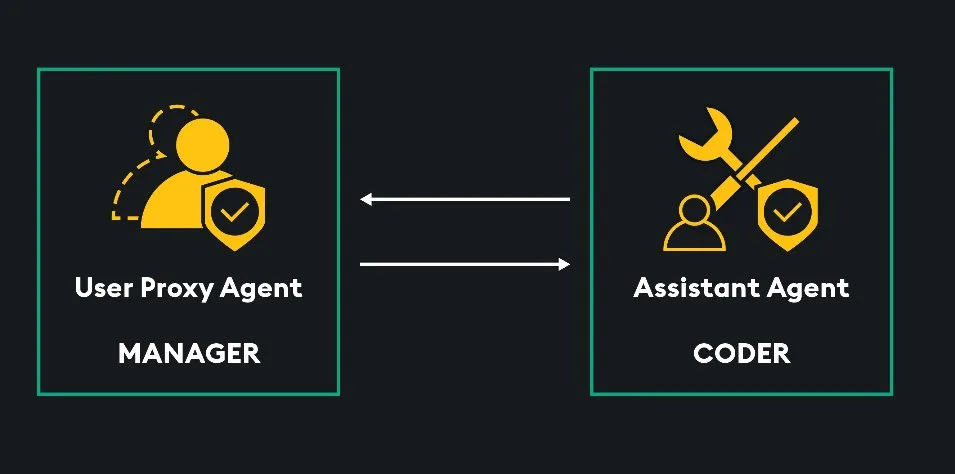
Their task is to develop some python code. The UserProxyAgent (manager) has the task and directs the AssistantAgent (coder) to write code to complete the task. The AssistantAgent received this message and writes the code. It then sends the code block back to the UserProxyAgent. The UserProxyAgent executes the code (just like a human would execute code to test it), and if it works it will return the code and the output of the code as a final answer. If there are any errors, it will report this to the AssistantAgent which will then adjust the code to fix it and send it back to the UserProxyAgent. This iterative process continues until the code works, or the developer set max iterations limit has been reached.
This is a relatively simple example, there are more complex use-cases such as doing function calling, multi-agent groups, retrieval augmented generation, etc. Note: Please see Microsoft’s GitHub for more examples.
AutoGen RAG Agent
AutoGen offers special agents for retrieving information from an external data source. These retrieval agents are called “RetrieveAssistantAgent” and “RetrieveUserProxyAgent”. When configuring RetrieveUserProxyAgent, specify the task and the path to the external data you want to retrieve from. Now that agent will have access to the information in that path.
The agent will chunk, convert to embeddings, and store in a vector database by default. Each of these steps could also be customized for example if we wanted to use KDB.AI as our vector database rather than the default Chroma vector database.
assistant_retriever = RetrieverAssistantAgent(
name = "Assistant_Retriever",
system_message = "You are an assistant to generate a helpful response",
llm_config = llm_config
)
RAG_retrieval_agent = RetrieveUserProxyAgent(
name="RAGUserProxyAgent",
human_input_mode="NEVER",
llm_config = llm_config,
max_consecutive_auto_reply=10,
retrieve_config = {
"task": "default",
"docs_path": "/path/to/docs.txt",
"embedding_model": "model_of_choice",
"chunk_token_size": 1000
}
)
assistant_retriever.reset()
RAG_retrieval_agent.initiate_chat(assisant_retriever, problem="The user prompt goes here")AutoGen Teachable Agent
The TeachableAgent from AutoGen makes it possible to teach an agent facts, user preferences, and skills that can be referenced outside the current chat instance. For example in a typical chat application, when a chat conversation is closed, facts from the conversation will not be available when a new chat is started. However, with a TeachableAgent, this information will be available in subsequent chats. The TeachableAgent stores its learnings in long-term memory (Vector database). When these facts are needed in a new conversation, they are retrieved into the context of the LLM for use.
teachable_agent = TeachableAgent(
name="teachableagent",
llm_config=llm_config,
teach_config={
"reset_db": False, #Use True to force-reset the memo DB, and False to use an existing DB.,\
"path_to_db_dir": "./tmp/interactive/teachable_agent_db"
}
)The Downside of Agents
Agents are very powerful and expand the capabilities of large language models but they come with some risks. First, we need to be weary of agents going into infinite loops – so always set a maximum iterations parameter! Secondly, agents are doing an initial call to a LLM for the up-front reasoning based on a user’s query. This will cost extra time and money. Thirdly, there is risk of agents being misused because they are so powerful and unregulated. Overall, agents can be a great addition to LLMs, but have some downsides to consider.
References & Learn More: