Overview
Unlike traditional AI systems that usually handle a single data type like text, the real world is multimodal. Humans use multiple senses to interact with their surroundings, and multimodal AI seeks to replicate this in machines. Ideally, we should be able to take any combination of data types (text, image, video, audio, etc.) and present them to a generative AI model all at the same time.
In addition, Large Language Models (LLMs) face constraints like limited context windows and fixed knowledge cutoff dates. To overcome these, we use Retrieval Augmented Generation (RAG), which has two stages: retrieval and generation. First, relevant data is fetched based on a user’s query. Then, this data helps the LLM craft a targeted response. The KDB.AI vector database supports this by storing embeddings of various data types, enabling efficient multimodal data retrieval. This ensures the LLM can generate responses by accessing a combination of the most relevant text, image, audio, and video data.
In this article we will explore both stages of multimodal RAG and how KDB.AI serves as the engine to power the retrieval process. We will understand how the embeddings of many different data types can be stored in a shared vector space, how cross-modal retrieval finds relevant data across multiple data types based on a user’s query, and how an LLM is augmented with retrieved data to generate a response for the user.
Multimodal Embeddings
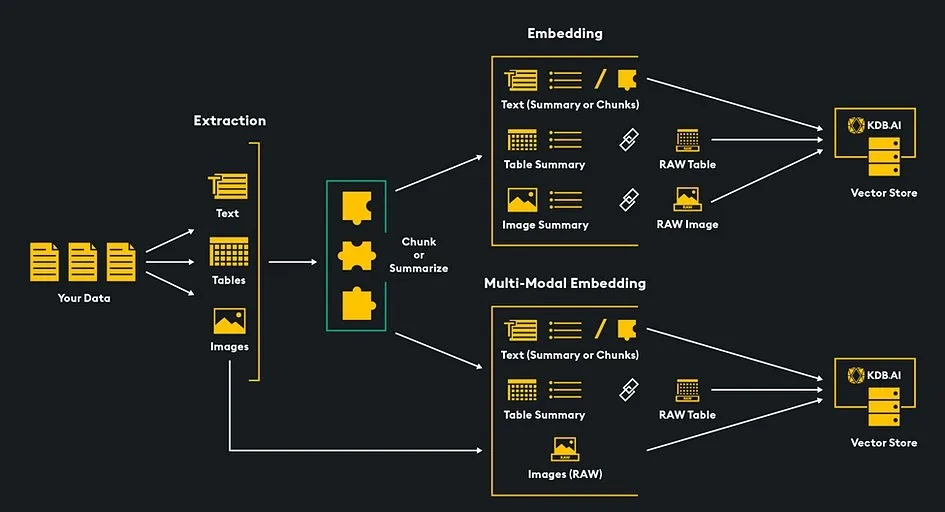
Many types of data have their own embedding models. There are text embedding models, image embedding models, audio embedding models, etc. The problem is that we cannot store the embeddings generated by each different model together in the same vector space, and therefore would not be able to execute vector search over all modalities simultaneously.
To enable multimodal RAG, we must first store multiple types of data such as images and text within a single vector space, allowing for concurrent vector searches across all types of media. We achieve this by embedding our data—transforming it into numerical vector representations—and storing these vectors in the KDB.AI vector database.
There are several methods we can use to store multiple data type embeddings within the same vector space:
- Multimodal Embedding Model
- Unify Modalities to Text
Multimodal Embedding Model
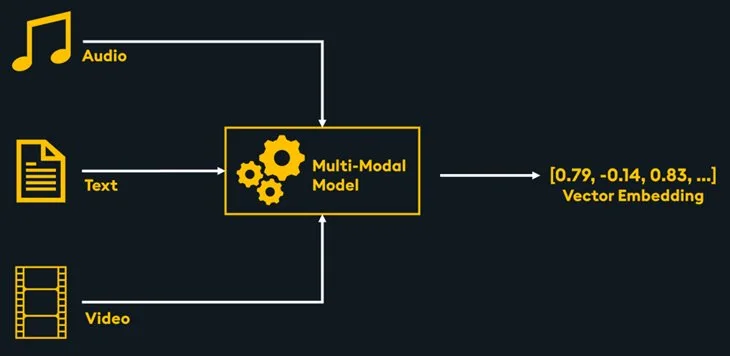
A multimodal embedding model facilitates the integration of diverse data types, such as text and images, into a unified vector space. This integration enables seamless cross-modality vector similarity searches within the KDB.AI vector database. The advantage of this method is that it directly embeds multiple data types without needing any summarization or transcription of non-text data.
There are several multimodal embedding models available including Meta’s ImageBind, OpenAI’s CLIP, visualBERT, CLAP, among others.
Embeddings generated with the same embedding model can be stored within the same vector store, meaning all embeddings are stored together in the same vector database, enabling multimodal retrieval. To see an example diving into multimodal embeddings with ImageBind, see this notebook.
Unify Modalities to Text
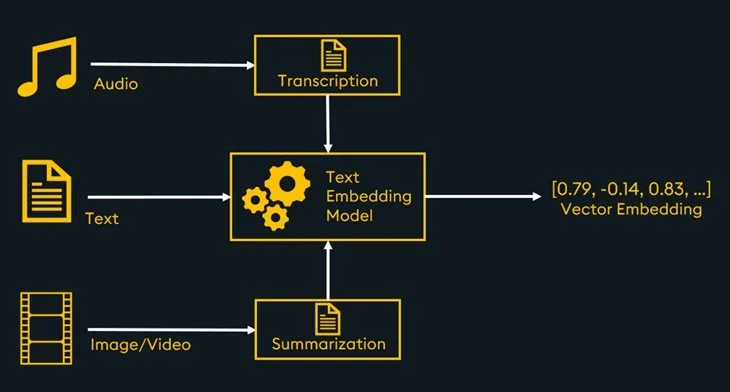
An alternative strategy for multimodal retrieval and RAG is to convert all data into a single modality: text. With this process, you only need a text embedding model to store all data within the same vector space. However, this approach incurs the additional cost of initially summarizing other data types such as images, video, or audio, which can be done manually or with the help of an LLM.
There are many text embedding models available including several options from sentence-transformers, and OpenAI.
With text, audio transcriptions, and image summaries embedded by a text embedding model and stored in the vector database, multimodal similarity search is enabled. For a code example, see this multimodal RAG sample notebook.
Cross-Modal Retrieval
Retrieving relevant multimodal data with similarity search is a key step to enable multimodal RAG. Cross-modal retrieval is the process of finding relevant data from one or more formats (e.g. images and audio) based on a query in another format (e.g. text). This integration of diverse data sources enhances similarity search by offering the option to query with different modalities such as images, text, or audio. The retrieved data from the cross-modal search can also contain multiple formats, serving to enrich the context and depth of information provided to the LLM for generation.
Multimodal Generation
The final step in the RAG workflow is generation, where the retrieved multimodal data from the vector search is injected into the prompt alongside the user’s query and sent to an LLM. By providing the LLM with a fusion of multiple data types like text, images, audio, the generation process produces responses that are more informed, relevant, and comprehensive, addressing the user’s query with greater depth and nuance.
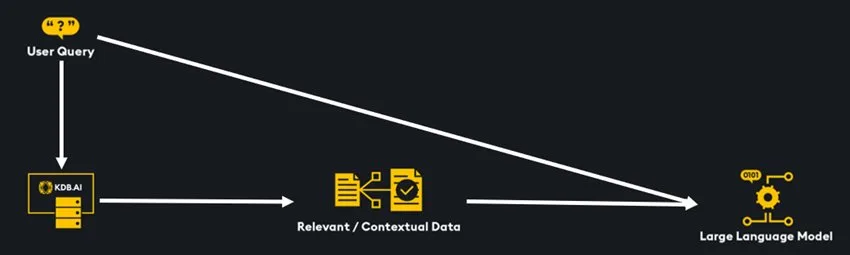
Generation can be completed with either a multimodal LLM that accepts multiple data types as inputs, or a text based LLM. With a text based LLM, we can pass in retrieved text, image summaries and text audio transcriptions. With a multimodal LLM we can pass in retrieved data in its original form as long as that data type is supported by the LLM.
Wrapping Up
The integration of various data types within the RAG pipeline enhances the LLM to generate more wholistic responses to a user’s queries. By leveraging multimodal embeddings and cross-modal retrieval, the RAG framework can access a richer and more diverse context, enhancing LLM generated responses. This approach opens new possibilities for applications requiring sophisticated understanding and synthesis of information across different modalities. As research and technology in this area continue to advance, we can expect to see further strides taken towards mirroring human-like perception in machines.