Overview
Chunking is a process where large pieces of data, such as text documents are divided into smaller, more manageable segments called chunks. These chunks are typically based on logical divisions in the data, such as sentences, paragraphs, or other structured elements in the document. There are many different methods to effectively chunk your data which will be discussed in this article, but the overall purpose is to make data easier to process, analyze, and to enable efficient retrieval of relevant information.
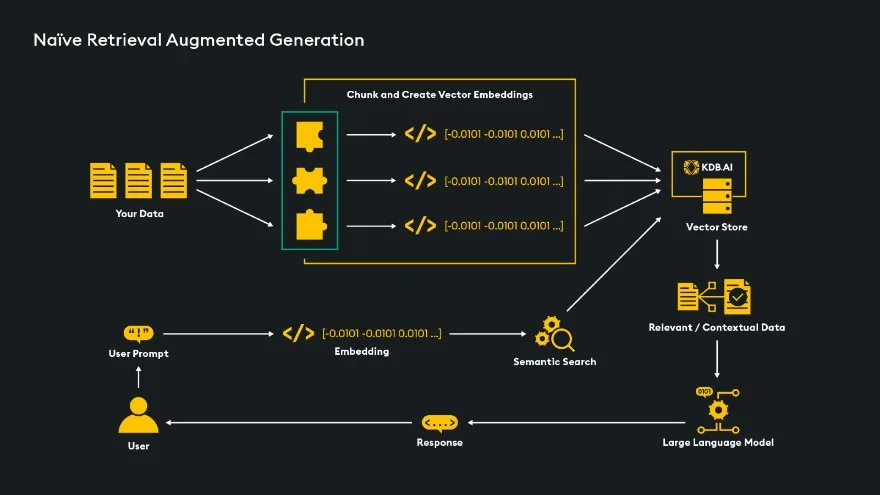
A main purpose of chunking is to prepare data for analysis by Large Language Models (LLMs). This analysis leverages Retrieval Augmented Generation (RAG), a method that selectively retrieves chunks of data from a vector database — data that the LLM has not been trained on — and introduces them to the LLM based on the user’s query. This process gives the LLM the context to answer questions regarding the retrieved chunks.
Why Chunk?
Chunking is important because any LLM will have a specified “context window” — limits on how many tokens can be input/output to and from the LLM per query. This context window makes it unrealistic to provide all our data to the LLM for each query, so we only want to feed the LLM relevant chunks of data, therefore not exceeding the token limit of the model.
Considerations
Before determining the chunk size and method of chunking to use, first look at the high-level use-case and overarching goal of the RAG pipeline:
- Structure/Length of Documentation: Are we dealing with long documentation or short texts like social media posts? Longer chunks make more sense for chunking up longer documents, while shorter chunks would be better for short texts like tweets.
- Embedding Model: There are many different embedding models available to run our chunks through to get them in vector embedding format and store them in a vector database. Embedding the chunks store them in a numerical format that captures contextual information about the chunk. If the goal is to embed shorter chunks, an embedding model designed for shorter texts like “Sentence-Transformers” would be a good option. Longer chunks would be best fit for embedding models designed to handle longer texts, for example OpenAI’s “text-embedding-3-small”.
- Expected Queries: Depending on the use-case, we would expect different types of queries from users. If we expect specific questions about granular topics, shorter chunk size could make more sense. If we expect more in-depth questioning, larger chunk sizes would likely be better because they will provide more context to the LLM.
Choosing Chunk Size
Chunk size can really affect your RAG pipeline performance! Small chunks, like single sentences, offer precision in retrieval but may lack sufficient context for quality generation, particularly with a restrictive top-k setting. On the other hand, larger chunks, such as entire pages, can hinder precise retrieval and slow down the LLM due to increased processing. They may also introduce multiple topics within a single chunk, reducing LLM effectiveness. Optimizing chunk size is essential to balance relevancy and efficiency in the RAG system.
Before choosing a chunking approach, you should understand the token limitations of the LLM you’re working with. For instance, some models have specific maximum token limits that include both input tokens and generated output tokens. It’s advisable to allocate a portion of this limit for output and reserve some tokens for the query, instruction prompts, and chat history if applicable. This leaves the remaining number of tokens for retrieved data.
In a RAG setup, we send a “top-k” number of relevant chunks to the LLM. To determine the maximum chunk size, we need to divide the remaining tokens by the number of chunks we plan to send. However, this is just a maximum, and smaller chunks can be used. The optimal chunk size will vary depending on the specific use case.
A Note on Context Windows: As LLM models improve over time, their context windows increase. This gives additional space for more information to be passed to an LLM for generation. However, there is some limitation to this because the more information included in the context window, the longer and more expensive the generation process will be. This is because the underlying transformer model’s processing time increases quadratically as context window increases. Read more here.
Chunking Methods
–Naïve Chunking:
- Fixed Sized Chunking: A method that quickly and efficiently chunks up data based on a developer-defined number of tokens. Additionally, there is the option to set a chunk overlap which should help to ensure any context related to a certain topic is not lost between chunks. You can also decide how to split by setting a “separator” variable, for example to split on paragraph use “\n\n”, or on sentences “\n”.
from langchain.text_splitter import CharacterTextSplitter
splitter = CharacterTextSplitter(
chunk_size = 100,
chunk_overlap = 10,
separator = "\n\n"
)
chunks = splitter.create_documents([text]) –Variable Size:
- Chunk by Sentence: There are smarter techniques to split by sentences than naïve sentence splitting. LangChain will integrate with popular natural language processing frameworks like NLTK and spaCy, which offer powerful sentence segmentation features.
NLTK Example:
from langchain.text_splitter import NLTKTestSplitter
splitter = NLTKTextSplitter()
chunks = splitter.split_text(text)SpaCy Example:
from langchain.text_splitter import SpacyTextSplitter
splitter = SpaCyTextSplitter()
chunks = splitter.split_text(text)- Recursive Character Text Splitter: This is a chunking method from LangChain, which gives the capability to set chunk size by number of characters and to overlap chunks. The method will recursively split documentation by paragraph, sentence, word, and character to best create related chunks.
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.document_loaders import TextLoader
#Load the documents we want to prompt an LLM about
doc = TextLoader("data/state_of_the_union.txt").load()
#Chunk the documents into 500 character chunks using langchain's text splitter "RecursiveCharacterTextSplitter"
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500, chunk_overlap=0)
pages = [p.page_content for p in text_splitter.split_documents(doc)]
–Structural Chunkers: There is inherent information that is built into the structure of a document, using chunkers that can split based on document structure should return better and more contextually stable chunks.
- MarkdownHeaderTextSplitter: This LangChain text splitter splits text within markdown documents based on headers in that document. The goal is to keep text with common context together. It splits text into chunks that contain the content of the text, and metadata entries of the hierarchy of headers that the text is located under.
from langchain.text_splitter import MarkdownHeaderTextSplitter
markdown_doc = "# Markdown Doc header1\n\n ## Header2\n\n section details\n\n ### Header3"
headers_to_split_on = [
("#", "Header 1"),
("##", "Header 2"),
("###", "Header 3"),
]
md_splitter = MarkdownHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
md_header_splits = md_splitter.split_text(markdown_doc)- HTMLHeaderTextSplitter: This LangChain text splitter divides HTML documents into chunks based on header structure. It creates chunks for each section or subsection, including metadata about the header hierarchy. This ensures related information is grouped together. The chunks can then be further processed with another chunker, like “RecursiveCharacterTextSplitter,” to adjust size and overlap. Here is an example of using HTML header splitter with Self-Query Retrieval.
from langchain.text_splitter import HTMLHeaderTextSplitter
from langchain.text_splitter import RecursiveCharacterTextSplitter
url = "https://kdb.ai/learning-hub/fundamentals/vector-database-101/"
headers_to_split_on = [
("h1", "Header 1"),
("h2", "Header 2"),
("h3", "Header 3"),
("h4", "Header 4")
]
html_splitter = HTMLHeaderTextSplitter(headers_to_split_on=headers_to_split_on)
html_header_splits = html_splitter.split_text_from_url(url)
splitter = RecursiveCharacterTextSplitter(
chunk_size = 800,
chunk_overlap = 40
)
chunks = splitter.split_documents(html_header_splits)–Summarization: Use LLMs to summarize the documentation and store summaries in the vector database. This will reduce the amount of data that would need to be stored in a vector database. These summarized documents can be linked back to the original documentation so relevant original chunks can be provided to the LLM for generation. This comes with the added cost of preprocessing your data with an LLM to do the summarization. Let us review three LangChain methods of summarization:
- Stuff: If the document can fit into the context window of an LLM, directly send the document into the LLM for summary.
from langchain.chains.summarize import load_summarize_chain
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-16k")
chain = load_summarize_chain(llm, chain_type = "stuff")
chain.run(docs)- Map-Reduce: When a larger document that does not fit into the context window of an LLM needs to be summarized we can use map-reduce. Map-reduce breaks large texts into smaller chunks, summarizes each chunk, and then combines all the summaries of all the chunks and creates an overall summary. Keep in mind that this makes many calls to the LLM so it can be costly.
from langchain.chains.summarize import load_summarize_chain
from langchain.chat_models import ChatOpenAI
from langchain.text_splitter import CharacterTextSplitter
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-16k")
splitter = CharacterTextSplitter(
separator="\n",
chunk_size=800,
chunk_overlap=80
)
#Chunk up your large document
chunks = splitter.create_documents(docs)
#Generate document summary
chain = load_summarize_chain(llm, chain_type="map_reduce")
summary = chain.run(chunks)- Refine: To summarize large documents that exceed an LLM’s context window, the Refine chunks approach starts by summarizing the first chunk, then incorporates each previous summary as context for the next chunk’s summary. This iterative process continues until all chunks are refined. However, this method involves multiple LLM calls, which can be costly.
from langchain.chains.summarize import load_summarize_chain
from langchain.chat_models import ChatOpenAI
from langchain.text_splitter import CharacterTextSplitter
llm = ChatOpenAI(temperature=0, model_name="gpt-3.5-turbo-16k")
splitter = CharacterTextSplitter(
separator="\n",
chunk_size=800,
chunk_overlap=80
)
#Chunk up your large document
chunks = splitter.create_documents(docs)
#Generate document summary
chain = load_summarize_chain(llm, chain_type="refine")
summary = chain.run(chunks)–Extraction: Many documents will hold multiple entity types, including text, tables, and images. To effectively use each of these in a RAG pipeline, we should extract these entities so they can be handled separately. There are many extraction tools available, including these two:
- LayoutPDFReader: LLMSherpa has a tool called LayoutPDFReader for parsing and providing hierarchical layout information on PDF documents. It can parse hierarchical information such as sections and subsections, paragraphs, tables, lists and nested lists. See this Colab notebook for an example.
- Unstructured: Extract, transform, and load (ETL) tool that has the capability to extract multi-modal elements from many types of documents including XML, PDF, PPTX, and HTML.
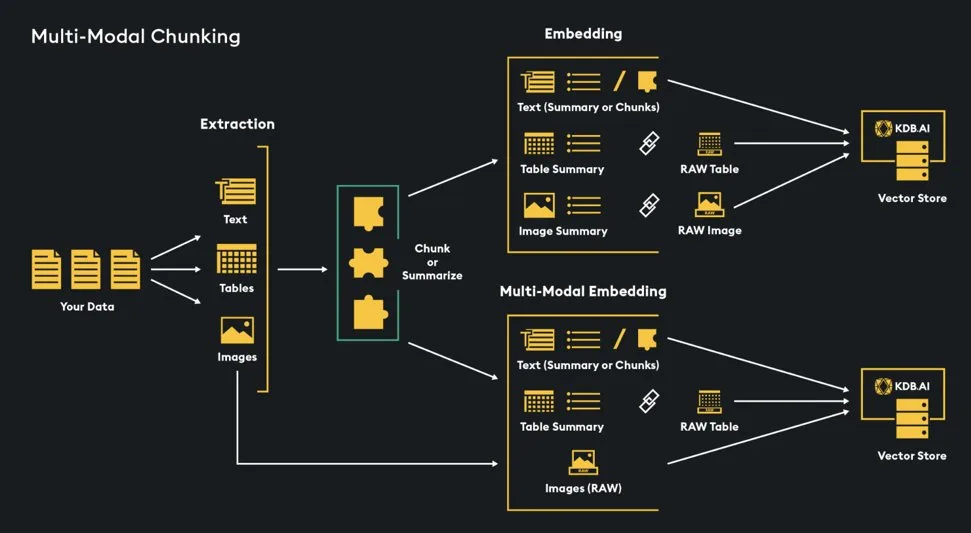
–Multi-Modal Documents (Text, Tables, Images): Naïve chunking is not an effective approach for handling tables and images, it could blindly split these elements. We need a smarter way to extract them from our input documentation. There are several options including the previously discussed “LayoutPDFReader”, as well as an ETL tool called “Unstructured” that specializes in extracting elements from many file types. The tables and images can be supplemented with titles and descriptions from the document itself or generated from an LLM. With multi-modal documents (text, images, tables), there are several options for how to store these in a vector database for retrieval.
- Multi-Modal Model: we could use a multi-modal embedding model and embed any images, the text (as a summary or in chunks), and a summary of any tables together. After relevant embeddings are identified, link directly to raw images, and tables and pass those alongside relevant text chunks into a multi-modal LLM for generation.
- Image Summary: A similar approach, however, we just use a description of any images rather than embedding the image itself and pass the relevant image descriptions to the LLM for generation.
- Image Summary + Raw Image: This approach embeds the image summary, but the summary links to the raw image. It allows the LLM to get passed the actual image without having to embed the image for retrieval.
References & Learn More: