Two of the most common vector indices—Flat and HNSW—are constrained by their reliance on in-memory storage. This dependency becomes a significant bottleneck when working with large datasets or systems with limited memory resources. To overcome these limitations, we’ve developed two innovative on-disk indexing solutions: qHNSW and qFlat.
By enabling on-disk storage with memory-mapped access that leverages our underlying technology of KDB+/Q, these indexes break free from the restrictions of traditional in-memory methods. This leads to more scalable and memory efficient indexing options due to KDB+/Q’s interplay between disk and memory. These advancements make qHNSW and qFlat ideal for a wide range of use cases, from enterprise-scale applications to resource-constrained edge environments.
The Role of Indexing in Vector Databases
At the core of vector databases lies the vector index, a mechanism that maps vector embeddings to a specialized data structure. By creating this index, databases achieve faster, and more memory-efficient searches compared to searching non-indexed raw embeddings. Indexes optimize search by facilitating efficient data access. In the case of approximate nearest neighbor indices like qHNSW, they go a step further by significantly narrowing the search space, which reduces computational overhead and speeds up query processing. This is particularly important as datasets grow, where the need for compactness and accessibility becomes essential.
Vector Databases Don’t Have to Be Expensive
One of the biggest misconceptions about vector databases is that they require significant hardware investments, especially as datasets grow into millions or billions of vectors. In-memory indexing demands high-capacity RAM and expensive infrastructure to ensure acceptable performance. However, on-disk indexing with qFlat and qHNSW offers a cost-effective alternative that reduces the Total Cost of Ownership (TCO) without compromising scalability or functionality.
How On-Disk Indexing Lowers Costs
- Reduced Hardware Requirements
On-disk indices store data on persistent storage rather than in memory. This means you don’t need expensive, high-capacity RAM to support large datasets. Instead, you can leverage more affordable storage options such as SSDs or even cloud-based storage solutions.
- Optimized Resource Utilization
By minimizing memory usage, on-disk indices like qFlat and qHNSW enable organizations to make better use of existing hardware. This is particularly advantageous in environments where memory is at a premium.
- Lower Power Consumption
Memory-intensive applications consume significantly more power than disk-based operations. By relying on on-disk indexing, you can reduce energy usage, which not only lowers operational expenses but also supports sustainability goals.
- Cost-Effective for Growing Workloads
On-disk indices allow you to defer costly hardware upgrades as your datasets grow. Instead of scaling memory, you can expand storage capacity incrementally, taking advantage of cost-efficient storage options like cloud block storage or high-capacity SSDs.
What is qHNSW?
The qHNSW index is a groundbreaking advancement designed to address the limitations of traditional HNSW (Hierarchical Navigable Small World) indices, which rely heavily on in-memory storage. This index is particularly useful in scenarios where high-speed, approximate nearest neighbor (ANN) searches are necessary. While not as accurate as exhaustive searches (like the qFlat index), it balances accuracy and efficiency, making it ideal for large-scale datasets. With hyperparameter tuning and filtering, accuracy can reach near exhaustive search levels.
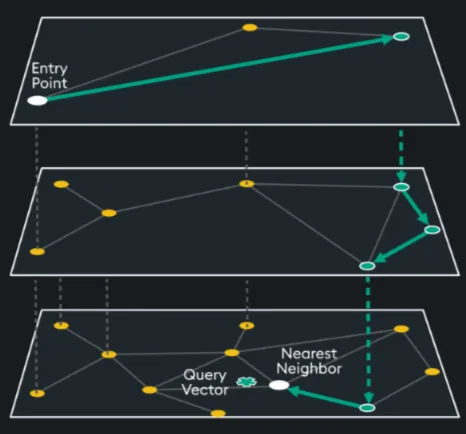
Key Features of qHNSW
- On-Disk Storage: Unlike its predecessors, qHNSW stores the index on disk with memory-mapped access, drastically reducing memory requirements.
- Incremental Disk Access: Queries read data incrementally from disk, optimizing memory utilization.
- Cost Efficiency: Disk-based storage is generally less expensive and energy-intensive than memory-based storage.
When to Use qHNSW?
- Large-Scale Datasets: The hierarchical graph structure allows for efficient and low memory indexing and querying. Additionally, with qHNSW, your dataset is not required to be entirely loaded into memory.
- Approximate Searches with High Recall: qHNSW provides a good balance between approximation and accuracy, making it ideal for scenarios where perfect accuracy is not mandatory but speed is critical.
- Memory Constrained Environments: qHNSW is a great fit if you need fast approximate search on a large dataset, but memory is a bottleneck (think IoT and edge devices for example).
See a full sample in our GitHub repository, or open the code directly in Google Colab.
qHNSW Performance Benchmarks
While throughput of a single qHNSW worker is outperformed by a single HNSW worker due to the trips to disk required with qHNSW, qHNSW allows more replications to be spun up – which enables a higher effective requests-per-second (RPS) throughput in a multi-tenanted system.
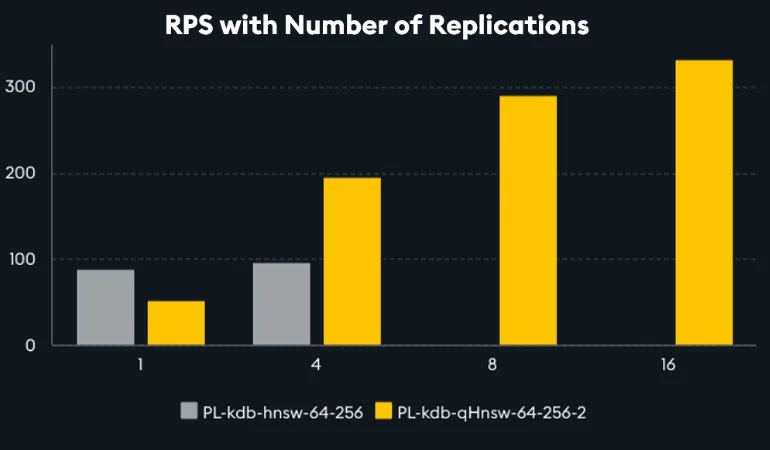
This makes qHNSW with memory mapping the go-to ANN index for multi-tenanted applications.
Note from the chart above, FAISS based HNSW did not run for 8 and 16 workers as the memory demand to hold 8/16 of the index in memory surpassed the systems resources.
What is qFlat?
The qFlat index provides an alternative approach to on-disk indexing with an emphasis on memory efficiency, making it perfect for resource-constrained environments like edge devices. Similarly to flat indices, qFlat is a great choice small to medium datasets up to a few million vectors, where accuracy is paramount. qFlat can even scale beyond the limits of a typical flat index, leveraging factors such as available compute resources, an effective partitioning strategy, and the use of lower-dimensional embeddings.
However, since qFlat performs an exhaustive search, its limitations include slower query performance compared to approximate nearest neighbor (ANN) indices like qHNSW, especially as dataset sizes grow beyond its optimal range. This makes it less suitable for real-time applications that have larger datasets.
Key Features of qFlat
- Low Memory Footprint: Both data insertion and vector searches are highly memory-efficient.
- On-Disk Storage: Like qHNSW, qFlat stores data on disk, offering scalability while maintaining minimal memory usage.
- Versatile Applications: Ideal for use cases where lightweight solutions are critical, such as IoT devices or mobile applications.
When to Use qFlat?
- Small to Medium-Sized Datasets: With datasets within 1-2 million vectors (sometimes more), the exhaustive flat search remains computationally realistic.
- High Accuracy Requirements: Unlike ANN methods, it guarantees exact results making it suitable for applications where precision is high priority.
- Low Dimensionality Embeddings: The lower the dimensionality of the embeddings stored within the index, the faster the exhaustive similarity search can be computed.
Download a sample Jupyter Notebook at the GitHub Repository, or open the code directly in Google Colab.
qFlat Performance Benchmarks
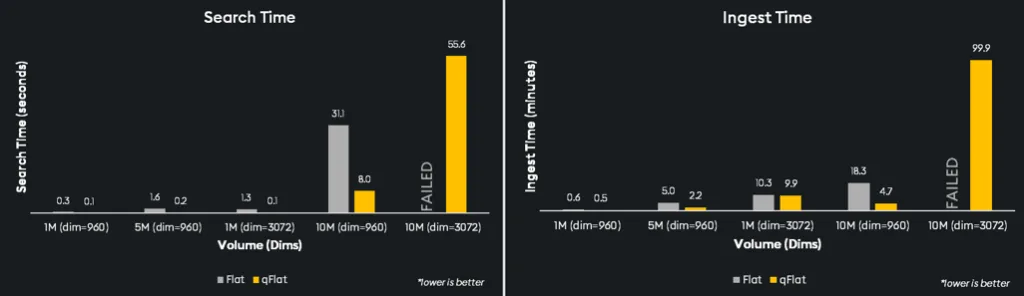
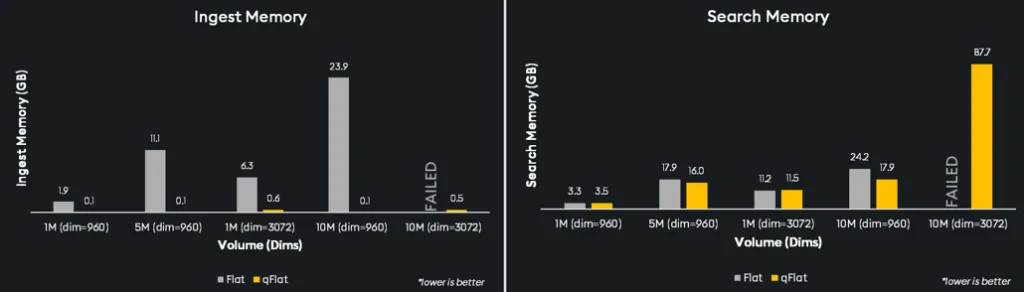

We see above that qFlat exceeds performance in both critical factors: time and memory. With ingest and search times far lower than traditional FAISS-based Flat, qFlat can process and execute searches through data much faster across different data densities and can even handle 10 million vectors on our test machines where Flat indexes failed.
Similarly, qFlat’s memory consumption for ingest is a fraction of what Flat offers across the board, while search memory is on par except at 10 million dimensions. qFlat provides an efficient solution for applications that anticipate scaling.
For developers looking to choose between Flat index options, KBD.AI’s qFlat offers a well-balanced, performant index option that delivers more accurate searches on less hardware and can reliably handle small to vast dimensions.
Considerations for On-Disk Indexing
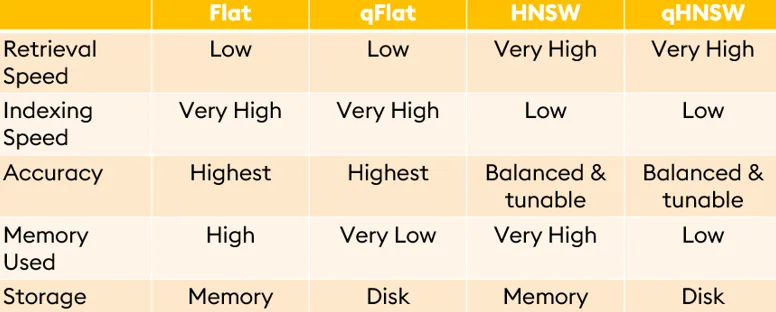
To maximize the efficiency and performance of on-disk vector indices like qHNSW and qFlat, several factors need to be considered:
- Disk Optimization: On-disk indexing performance is heavily influenced by disk speed. Faster storage solutions such as SSD (Solid State Drives) or NVMe disks can significantly reduce latency during both data retrieval and writes. Avoid traditional HDDs for high-performance applications, as their slower speeds can become a bottleneck.
- Read/Write Access: Ensure the system has adequate permissions to read and write to the disk. Misconfigured permissions can lead to errors during index creation, updates, or query operations. Additionally, it’s important to monitor disk space usage, as insufficient storage can disrupt indexing processes.
- Disk Throughput and IOPS (Input/Output Operations Per Second): For high query loads or real-time search applications, a disk with high IOPS is critical. Higher throughput allows for faster sequential reads and writes, which is especially beneficial when handling large datasets.
- Index Placement: Store the index on local disks rather than remote storage whenever possible to minimize latency caused by network overhead. If remote storage is unavoidable, consider using solutions optimized for high-speed access, such as network-attached SSDs.
- Data Consistency and Backup: As the index is stored on disk, it’s essential to implement a backup strategy to protect against hardware failures or data corruption. Regular snapshots or replication to redundant storage systems can safeguard your data.
- Concurrent Access: If multiple processes need to access the index simultaneously, ensure that the storage system supports concurrent read/write operations efficiently. Tools or mechanisms for managing file locks may be required to avoid conflicts.
By addressing these considerations, you can fully leverage the benefits of on-disk vector indices, achieving a balance between memory efficiency, scalability, and performance.
Scale Smarter with KDB.AI
By offering qHNSW and qFlat, KDB.AI empowers users to overcome the memory limitations of traditional indices. Whether you’re building a scalable enterprise solution or a lightweight edge application, these indices open new possibilities for efficient and effective vector indexing.