Overview
A vector database’s main function is to perform efficient similarity searches across vector embeddings of unstructured and structured data. These similarity searches, which are both rapid and precise, can be further enhanced through built-in methods such as metadata filtering. This article will delve into how metadata filtering can both speed up and enhance the precision of your vector searches.
Embeddings & Vector Similarity Search
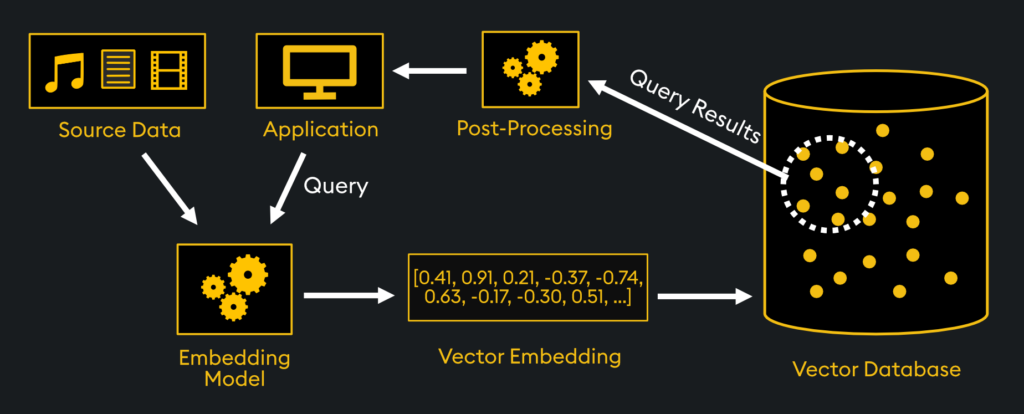
To begin, let’s understand the architecture of how the KDB.AI vector database operates. First, source data is ingested and processed through an embedding model. This model, typically a neural network, converts raw data into a vector embedding – a numerical vector that captures the properties, relationships, and the semantic meaning of the original data. The original data is now in the form of a high-dimensional vector which can be stored within the vector database. Additionally, we can attach metadata to each vector. Metadata columns are extra fields of data that further describe what is held within the vector embedding. This metadata can later be used as filters for our similarity searches.
After the data has been embedded and stored in the KDB.AI vector database, a user can perform a similarity search by entering a natural language query. This query is then embedded to generate a query vector, and a similarity search is conducted between this query vector and the vectors present in the database. This search will identify the most similar vectors to the query vector and return them to the user. See example notebooks: https://github.com/KxSystems/kdbai-samples
Metadata Filtering
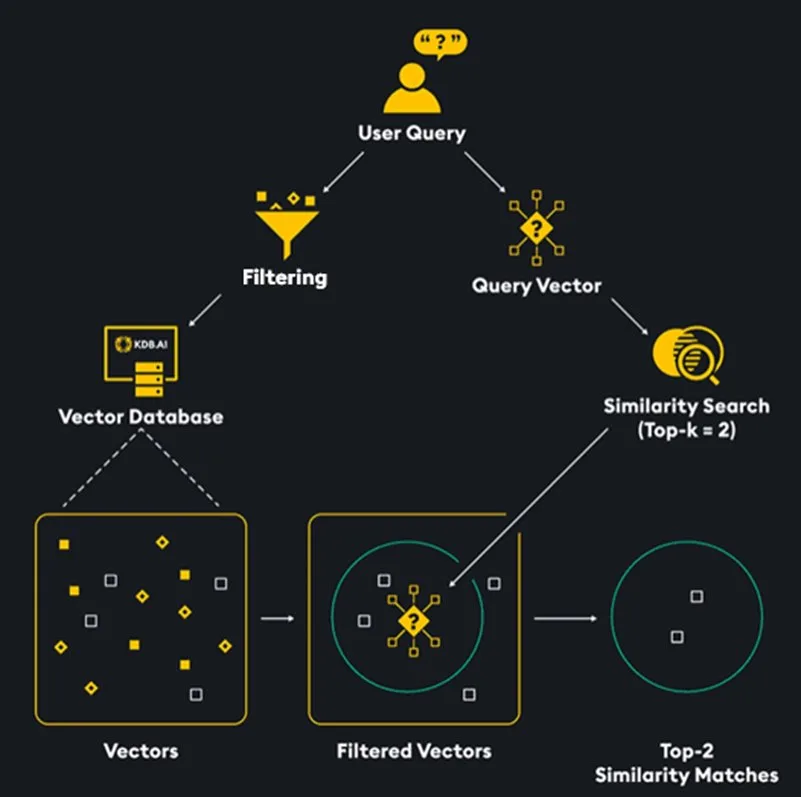
Each vector in the database can be associated with various metadata. This metadata can be leveraged to enhance our querying process by specifying filters along with our queries. By filtering our search, we effectively narrow down the search space, thereby reducing the number of vectors that need to be searched. Think of this as like a ‘where’ statement in SQL.
Metadata Filtering Implementation
Examples of metadata include dates, times, genres, categories, names, types, descriptions, and others, depending on your specific use-case. In the following example, we are creating a table in KDB.AI where metadata columns contain supplementary information about a dataset of movies. The metadata fields include ReleaseYear, Title, Origin, Director, Cast, Genre, and Plot. The final column is the “embeddings” column, where the plot of each movie is stored as a vector embedding. The purpose of this table is to facilitate vector similarity search on movie plots, assisting the user in discovering similar movies and providing metadata fields for further refinement of the results.
#Set up the schema for KDB.AI table,
#Embeddings column with 384 dimensions, L2 = Euclidean Distance, index = flat
table_schema = [
{"name": "ReleaseYear", "type": "int64"},
{"name": "Title", "type": "str"},
{"name": "Origin", "type": "str"},
{"name": "Director", "type": "str"},
{"name": "Cast", "type": "str"},
{"name": "Genre", "type": "str"},
{"name": "Plot", "type": "str"},
{"name": "embeddings", "type": "float64s"},
]
# Set up the index with 384 dimensions, Euclidean Distance, and flat index
indexes = [
{
"name": "flat_index",
"type": "flat",
"column": "embeddings",
"params": {"dims": 384, "metric": "L2"},
}
] Conducting a similarity search on a KDB.AI vector database table consists of three elements, the query vector, the top-n results, and the filter. The query vector contains the vector embedding of the user’s natural language query. The top-n parameter defines how many results the search will return, for example n=3. The filter is where metadata filters are defined by the user.
The filters are applied to the vector database, excluding any vectors that do not match the specified criteria. In reference to the example below, this means that any vectors with a director other than George Lucas and a release year other than 1977 are not considered during search. Metadata filtering greatly enhances both the accuracy and efficiency of the similarity search, particularly with large-scale data.
# Search query specifying the query vector, top-n=3, and metadata filters
table.search(
vectors=query_vector,
n=3,
filter=[("like", "Director", "George Lucas"),("=", "ReleaseYear", 1977)]
) Supported Filter Functions
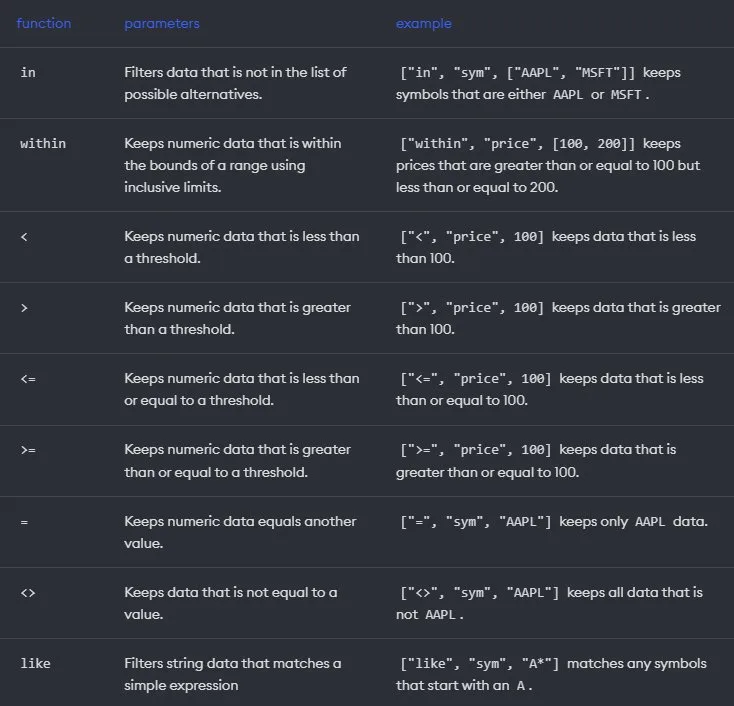
KDB.AI has a variety of supported metadata filtering functions:
Automatic Metadata Tagging & Filtering
Frameworks such as LangChain and LlamaIndex provide features that automatically annotate incoming queries with metadata and perform filtering in the background. Auto-Retrieval from LlamaIndex and Self-Querying from LangChain both leverage an LLM to handle metadata tagging and filtering. This method can effectively boost the relevance of data retrieved from a vector database without requiring the user to manually apply metadata filters.
Wrapping Up
Incorporating metadata filtering into vector similarity searches significantly enhances their efficiency and precision. By applying targeted filters, users can narrow the search scope, leading to quicker processing and more accurate retrieval. KDB.AI provides a user-friendly and free way to get started with leveraging vector databases with metadata filtering. Explore the capabilities of KDB.AI’s metadata filtering with our metadata filtering sample today!