Despite their impressive capabilities, computers cannot easily understand text, images, audio, or other human-readable data formats. When it comes to the analysis of these types of data, we can instead represent them as numerical “vectors” which can be better processed computationally. This vectorization can involve many steps, and often involves deep neural networks outside the scope of this article, however, this article will equip you with the basic concepts. Let’s dive in.
What is a Vector?
A vector is a mathematical way to represent a fixed-length array of numbers representing both magnitude and direction. To have both magnitude and direction, a vector must have at least 2 dimensions, which is plotted below at [1,1]. This can also be expanded to 3 dimensions as shown with the vector [1,1,1]:
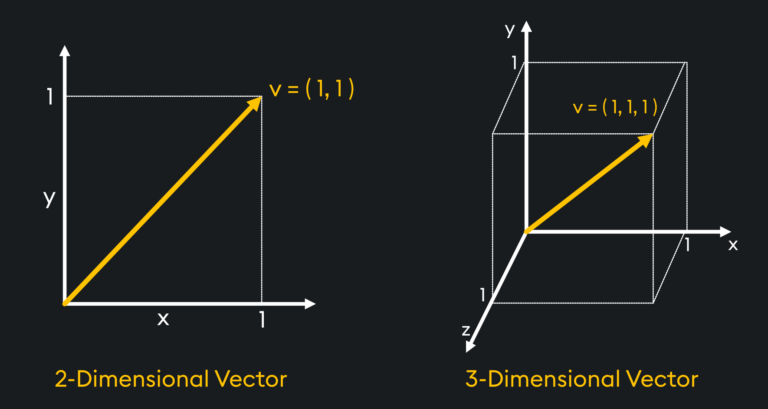
In Machine Learning applications, vectors can have thousands of dimensions – too many to even attempt to visualize. The key point to note here is once something has been represented as a mathematical vector, it opens it up to mathematical vector operations such as measuring distances, calculating similarities, and performing transformations. These operations become crucial for a wide range of tasks, including similarity search, clustering, classification, and uncovering patterns and trends.
What Is A Vector Embedding?
A vector embedding, or simply “an embedding”, refers to a vector which has been created as the numerical representation of typically non-numerical data objects . Embeddings capture the inherent properties and relationships of the original data in a condensed format and are often used in Machine Learning use cases. For instance, the vector embedding for an image containing millions of pixels, each with a unique color, hue, and contrast, may only have a few hundred or thousand numbers. In this way, embeddings are designed to encode relevant information about the original data in a lower-dimensional space, enabling efficient storage, retrieval, and computation. Simple embedding methods can create sparse embeddings, whereby the vector’s values are often 0, while more complex and “smarter” embedding methods can create dense embeddings, which rarely contain 0’s. These sparse embeddings are often higher dimension than their dense counterparts however, and hence require more storage space.
Unlike the original data, which may be complex and heterogeneous, embeddings typically strive to capture the essence of the data in a more uniform and structured manner. This transformation process is performed by what’s known as an “embedding model” and often involves complex machine learning techniques. These models take in data objects, extract meaningful patterns and relationships from this data, and return vector embeddings which can later be used by algorithms to perform various tasks. There are many sophisticated embedding models which are openly available online, examples of which we will give in a later section of this article.
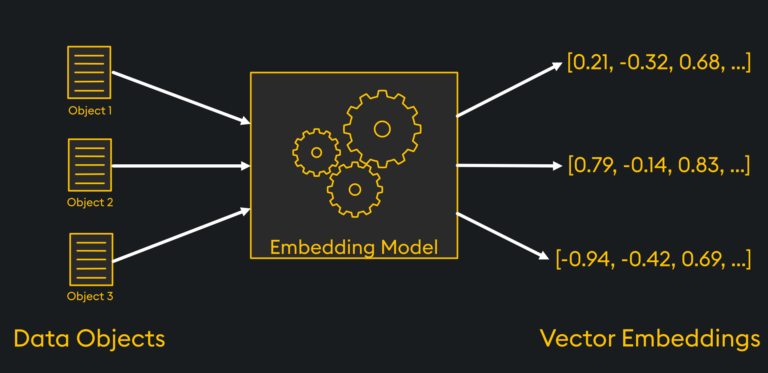
How Are Vector Embeddings Generated?
The precise information contained in an embedding depends on the specific type of data being embedded and the embedding technique employed.
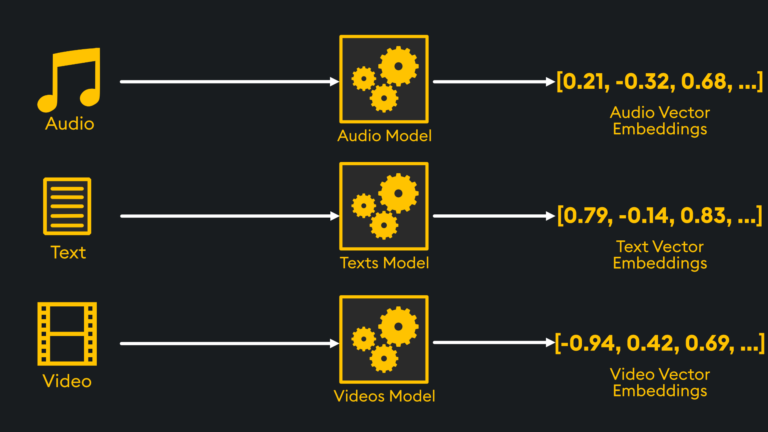
In general, embeddings aim to capture semantic, contextual, or structural information relevant to the specific task at hand. Each embedding model utilizes specific techniques and algorithms tailored to the type of data being dealt with and other characteristics of the data being represented. Here, we can give examples of what features may be encoded for text, image, audio, and temporal data and provide a list of common techniques used to achieve this:
Text Embeddings: captures the semantic meaning of words and their relationships within a language.
- Example – it might encode semantic similarities between words, such as “king” being closer to “queen” than to “car”.
- Common models:
- TF-IDF (Term Frequency – Inverse Document Frequency) creates sparse embeddings by assigning weights to words based on their occurrence frequency in a document relative to their prevalence across the entire dataset.
- Word2Vec creates dense vector representations that capture semantic relationships by training a neural network to predict words in context.
- BERT (Bidirectional Encoder Representations from Transformers) creates context-rich embeddings that capture bidirectional dependencies by pretraining a transformer model and using this to predict masked words in sentences.
Image Embeddings: captures visual features like shapes, colors, and textures.
- Example – it might encode contrasts between colors; for example, that orange objects to be more similar to yellow objects than they are to black objects.
- Common models:
- Convolutional Neural Networks (CNNs) create dense vector embeddings by passing them through convolutional neural network layers that extract hierarchical visual features from the images.
- Transfer Learning with Pretrained CNNs like ResNet and VGG create embeddings by fine-tune pre-trained CNNs which have already learned complex visual features from large datasets.
- Autoencoders are neural network models which are trained to encode and decode images by generating embeddings that capture compact representations of the raw images.
Audio Embeddings: captures audio signals like pitch, frequency, or speaker identity.
- Example – it might encode the sound of a piano and a guitar to have distinct numerical representations reflecting the acoustic features of each sound, enabling differentiation.
- Common models:
- Spectrogram-based Representations creates embeddings by first converting the audio into visual representations, like spectrograms, and then apply image-based methods to embed these images as vectors.
- MFCCs (Mel Frequency Cepstral Coefficients) create vector embeddings by calculating spectral features of the audio and using these to represent the sound content.
- Convolutional Recurrent Neural Networks (CRNNs) create vector embeddings by combining convolutional and recurrent neural network layers to handle both spectral features and sequential context in creating informative audio representations.
Temporal Embeddings: captures the temporal patterns and dependencies in time-series data.
- Example – it might encode the heart rate time-series from a person at rest to be more similar to a person sleeping than it would to somebody who is running a marathon.
- Common models:
- LSTM (Long Short-Term Memory) models create embeddings by capturing long-range dependencies and temporal patterns in sequential data using a recurrent neural network (RNN) architecture.
- Transformer-based Models create vector embeddings by using a self-attention mechanism to capture complex temporal patterns in the input sequence.
- Fast Fourier Transform (FFT) creates vector embeddings that capture periodic patterns and spectral information in the temporal data by converting it into its frequency-domain representation and extracting frequency components from this.
What Can You Do With Vector Embeddings?
So, what can we do with these vector embeddings once we have obtained them?
- Similarity search: Use embeddings to measure the similarity between different instances. For example, in Natural Language Processing (NLP), you can find similar documents or identify related words based on their embeddings.
- Clustering and classification: Use embeddings as the input features for clustering and classification models to train machine-learning algorithms to group similar instances and classify objects.
- Information retrieval: Utilize embeddings to build powerful search engines that can find relevant documents or media based on user queries.
- Recommendation systems: Leverage embeddings to recommend related products, articles, or media based on user preferences and historical data.
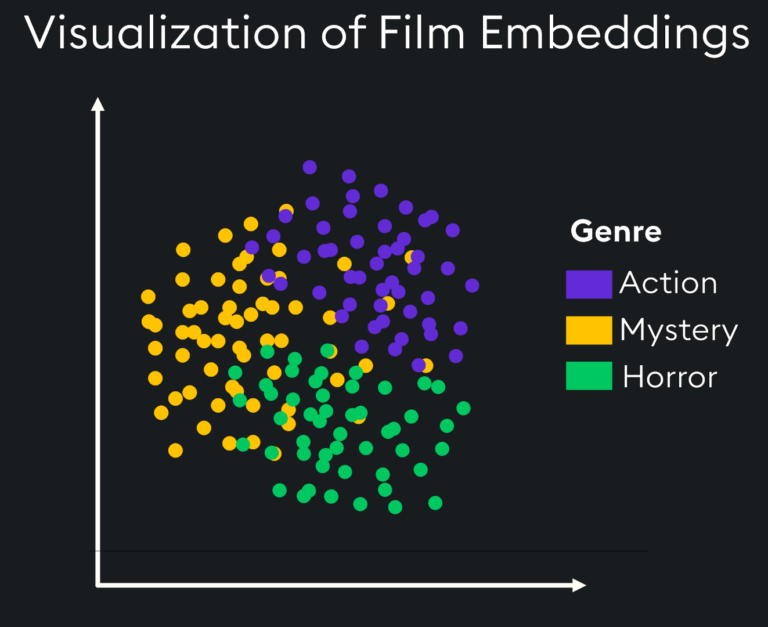
- Visualizations: Visualize embeddings in lower-dimensional spaces to gain insights into the relationships and patterns within the data.
- Transfer learning: Use pre-trained embeddings as a starting point for new tasks, allowing you to leverage existing knowledge and reduce the need for extensive training.
Vector Embeddings: An AI Foundation
Vector embeddings play a pivotal role in bridging the gap between human-readable data and computational algorithms. By representing diverse data types as numerical vectors, we unlock the potential for a wide range of Generative AI applications. These embeddings condense complex information, capture relationships, and enable efficient processing, analysis, and computation. Armed with vector embeddings, you can explore and transform data in ways that facilitate understanding, decision-making, and innovation across any organization.
To continue learning about how embeddings are used by vector databases, check out our article Methods of Vector Similarity.