Introduction
Do you like horror stories? Mystery? Romance? Imagine you went to a library and these books weren’t arranged by genre. Even worse, imagine the genres were never defined. How would you find what you were looking for?
In a vector database, data is automatically arranged spatially by content similarity, and that similarity is on content meaning rather than just keywords. With advances in Machine Learning, machines are now able to understand the content we provide to them. So, in our library analogy, all the books would be automatically arranged in the vector database by similar genre, even if genre wasn’t pre-defined. This is because books would be modeled together by the database’s ability to understand context. What’s more, vector databases allow a high degree of granularity on the similarities, so books could also be searched by author’s writing style, story plots, and more. All within the same storage structure, without you having to manually label or tag the content itself for exact lookups that have no contextual grounding.
This is why vector databases are so revolutionary. Similarity search is so fundamental that it is powering a new wave of applications in AI. Similarity search is especially powerful when you also factor vector databases’ ability to process unstructured data with ease, something which traditional databases struggle to handle.
The applications being developed today are a step-wise improvement of those in the past. Some include:
- Intelligent Chatbots
- Recommendation Systems
- Anomaly and Fraud Detection
- Image, Audio, and Video Generation
- Search Engine Optimization
- and more…
There are some key concepts to create and operate vector databases, detailed in our other articles:
As you progress on your learning journey, it’s recommended you check out these articles, however, this article is provided as a high-level overview of how vector databases work, what they’re used for, and their benefits.
How Vector Databases Work
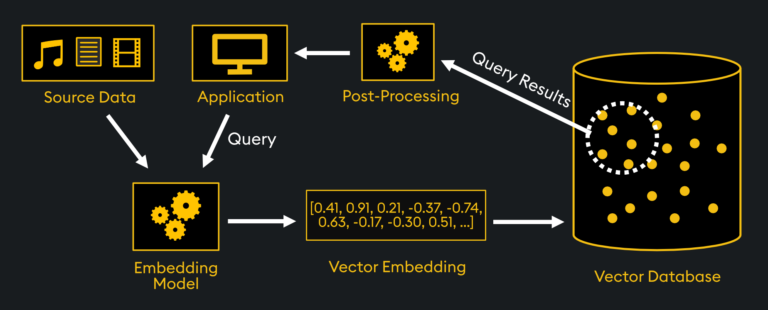
The “meaningful” representations of data are stored in what’s known as “vector embeddings.” These vector embeddings, often generated by Machine Learning models, are hundreds of thousands of elements long, capturing up to thousands of characteristics. Vector embeddings are created outside of the vector database by taking your source data and passing it through an “embedding model.”
In our library example, the embedding model can be considered the process of classifying a book by genre and other attributes. These special vector embeddings represent the data in “vector space” of a vector database, where similar vectors are stored spatially. From there, a “vector index” is created by the vector database which serves as an efficient “road map” of where all the vectors are. The vector index could be considered the library catalog in our library example, while the vector database engine is the librarian:
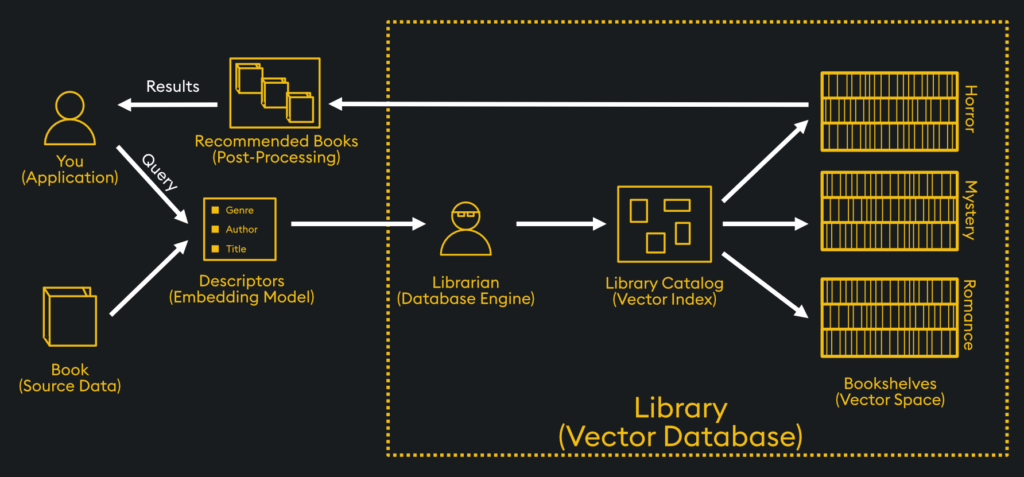
When querying the vector database from an application, various similarity metrics can be used to find similar vector embeddings and are chosen based on the application needs. In our library example, the application is you, and the query is your request for a particular type of book. A similarity search is computed between that query vector and other stored vector embeddings by the vector database engine. Once the results are obtained, they are ranked and retrieved, then post-processed before returning the results back to the application.
The post-processing and query characteristics depend on the application being used. One example could be a recommendation system where books similar to your query are ranked, filtered, and returned as a recommended list. Another application could be Large Language Model (LLM) text generation, where a custom story is written based on your interests. There are many different applications so let’s discuss a few.
Key Applications of Vector Databases
There are countless applications for vector databases, but some of the major ones include:
- Generative QA Chatbots: Utilizing LLMs like GPT-4, chatbot applications like ChatGPT are possible that stochastically generate responses to queries based on source text
- Anomaly Detection: Just as similar data can be found, dissimilar data can be identified just as easily. This opens up wide applications in anomaly detection.
- Recommendation Systems: By finding similar items in vector space, and utilizing historical personal preferences, highly effective recommendation systems can be built
- Image, Audio, and Video Generation: Utilizing text-to-image models, image generation tools like DALL-E and Midjourney can be created
- Search Engine Optimization: Rather than focusing on keyword search, sematic meaning can be utilized for search such as that used by Bing
- Proprietary Knowledge Bases: Companies and organizations may embed sensitive documents and files into their vector database to create a semantically structured, searchable, knowledge base.
- Code Generations: Utilizing LLMs like GPT-4, code generation, completion, and debugging tasks can be completed using tools like Github Copilot.
Analogy to Traditional Databases
In traditional databases, data is stored exactly as-is. There is no transforming of the data into another representation. This becomes extremely difficult for unstructured data, which is estimated to be up to 90% of all data generated today. There are seven types databases, each with their own benefits:
- Relational Databases
- NoSQL Databases
- Time-Series Databases
- In-Memory Databases
- Document Databases
- Graph Databases
- Vector Databases
The most common and oldest type of database used today is the Relational Database. If you are familiar with this type of database, you might benefit from the following mapping to Vector Databases:
| Relational Database | Vector Database |
|---|---|
| Database | Collection |
| Table | Vector Space |
| Row | Vector |
| Column | Dimension |
| Index | Index |
| Insert | Insert |
| Update | N/A |
| Delete | Delete |
| Join | N/A |
Benefits of using a Vector Database
Technically speaking, you could store all of your vector embeddings in a numpy array using Python, or a traditional database with vector capabilities. However, these have many downsides compared to using a native vector database:
- Temporal Search: KDB.AI offers a time-series overlay where different search mechanisms can be windows to a time range through vector-based processing.
- Native Similarity Search: Built-in similarity search is more efficient in native vector databases
- Optimized Indexing: Indices are generated once, and from advanced methods. Without a database, all indices must be generated every time the data updates.
- Scalability: Vector databases use special techniques to optimize memory usage and retrieval speed, which leads to increased scalability
- Data Compression: Vector databases use special data compression methods that optimize memory usage
- Real-time: KDB.AI is better suited to handle real-time data updates and retrieval due to its natively vectorized data processing and history as the fastest time-series database in the world
- Multi-modal Data: Vector databases offer superior support for various data types, including text, video, audio, and images. They are designed to handle high-dimensional vectors.
Learn more
In this article we overviewed the mechanics of how a vector database works, the applications it’s used for, comparisons with traditional databases, and benefits of using a native vector database. To learn more about specific vector database mechanics, check out our articles on the KDB.AI Learning Hub.