Semantic search allows users to perform searches based on the meaning or similarity of the data rather than exact matches. The initial query is converted into a vector embedding and then paired with similar embeddings that exist within that database. This means that even if the query and data in the database are not identical, the system can identify and retrieve the most relevant results based on their semantic search.
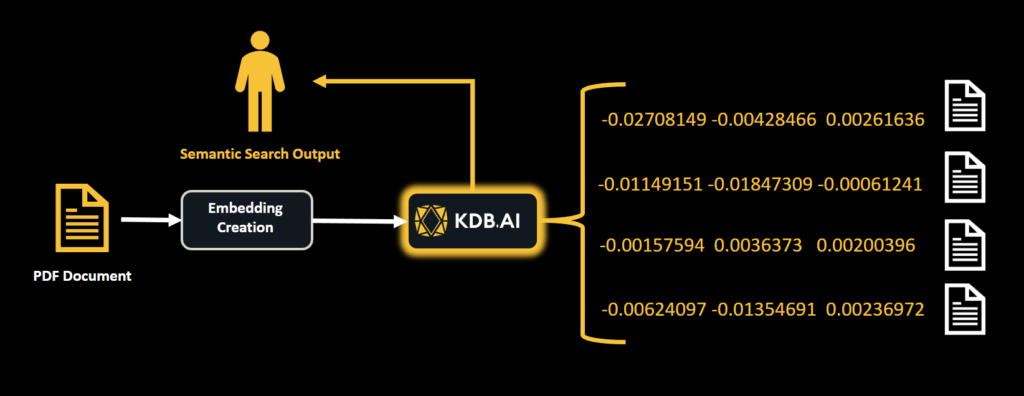
To begin, we will load a PDF document and split it into sentences. In this example, we’ll be using a research paper that presents information on the formation of Interstellar Objects in the Milky Way. We will then create some vector embeddings based on the information within these sentences and store these in our KDB.AI vector database. Finally, we will perform semantic search to retrieve similar records.
Download the Jupyter Notebook and any accompanying files at the repository on GitHub.