Learn how to harness the power of Retrieval Augmented Generation (RAG) through this hands-on guide using LangChain, KDB.AI, and various Large Language Models (LLMs). RAG is an advanced prompt engineering technique that enables LLMs to access real-time, contextually accurate information from external knowledge bases, enhancing their ability to provide up-to-date and relevant responses.
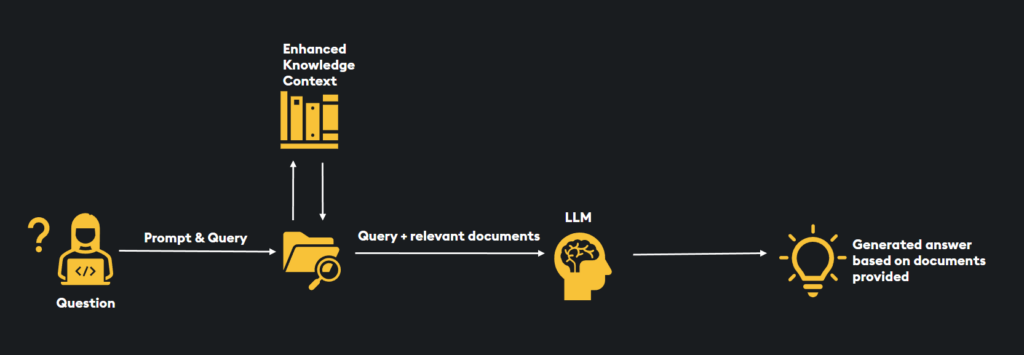
While Large Language Models excel at generating human-like text, they face limitations in staying current with real-world events as they rely on static training data. RAG addresses this challenge by allowing LLMs to tap into external knowledge sources, ensuring that their responses are enriched with timely information. In this tutorial, we’ll cover the process of setting up RAG with LangChain, from loading text data to KDB.AI and performing Retrieval Augmented Generation using OpenAI and HuggingFace LLMs.
Retrieval Augmented Generation, as demonstrated in this tutorial, offers a powerful approach to leverage the capabilities of language models and real-time information retrieval. By combining these techniques, you can provide more precise and contextually relevant responses, making it valuable for various applications, including chatbots and content generation.
Download the Jupyter Notebook and any accompanying files at the repository on GitHub.