Semi-structured data containing important business knowledge is often embedded in complex file formats like PDFs, which are notoriously challenging to work with. Consider the many documents in PDF format, such as earnings call transcripts, investor reports, news articles, and research papers. Efficiently extracting embedded information such as text, tables, images, and graphs from these files is essential.
In this sample, learn how to use LlamaParse, an LLM enabled document parsing technology designed to extract embedded data from complex documents.
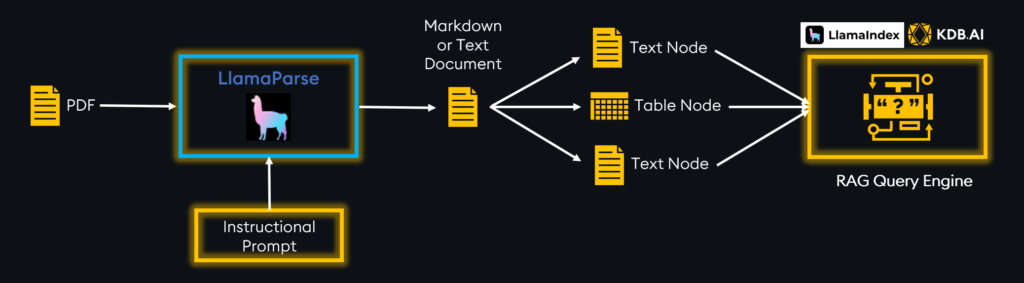
With LlamaParse, we can cleanly extract embedded information from complex documents and build retrieval augmented generation (RAG) pipelines upon this data. To customize this parsing further, we will explore sending customized instructional prompts to LlamaParse to improve the parsing. Indicate how you want the output formatted or ask the LLM to do preprocessing like sentiment analysis, language translation, summarization, and more.
Download the Jupyter Notebook at the GitHub Repository, or open the code directly in Google Colab.