Introduction
Retrieval augmented generation (RAG) empowers users to prompt a large language model (LLM) for information that the model has not been previously exposed to. This approach combines the capabilities of LLMs with information retrieval and similarity search techniques applied to relevant documentation, such as enterprise data.
There are two steps of RAG. First, retrieval, to extract relevant data. Secondly, generation, where the LLM generates a response based on the retrieved data.
Tools:
LangChain: An open-source framework that helps developers to build applications that are powered by LLMs. Functionality includes loading, processing, and indexing data, providing agent and tool capabilities to custom workflows, and chaining together LLMs and external components to develop applications.
LlamaIndex: A data framework that helps developers to build applications powered by LLMs. LlamaIndex is focused on efficient processing of large datasets, search, retrieval, and evaluation.
KDB.AI: A vector database that powers relevant search that includes temporal and semantic context, gives the ability to analyze data over time, and allows users to search and index their data with unmatched speed.
Methodologies
Naïve RAG
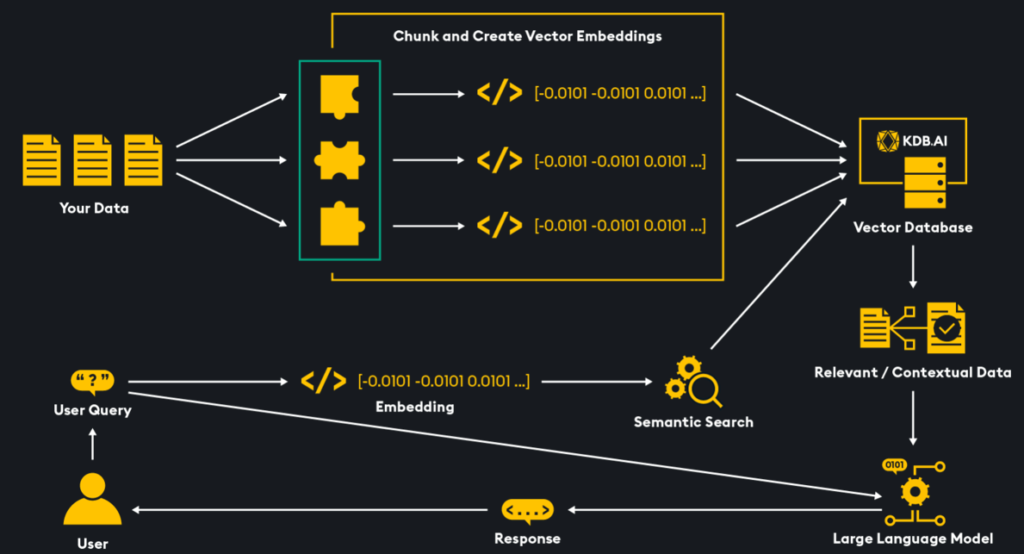
Walking through this step-by-step (Full code available here):
- Data Ingestion: LangChain and LlamaIndex have the capability to ingest many types of files including .pdf, .docx, .xlsx, .csv, etc.
- Chunking: Now, the data needs to be divided into smaller segments known as chunks. This step is essential due to the token constraints of LLMs, which limit the amount of data they can process. By chunking the data, we ensure that smaller and more relevant pieces are sent to the LLM, avoiding any token limitations.
- Create Vector Database using KDB.AI: Next, we must create a vector database; we can do this for free by using KDB.AI. You can sign up for KDB.AI here. Once you have an account, get your API key and endpoint which will be used to create a table. To create a vector database table, first create a schema which defines what columns will be within the table.
# Create the table schema
rag_schema = [
{"name": "id", "type": "str"},
{"name": "text", "type": "bytes"},
{"name": "embeddings", "type": "float32s"}
]
# Define the index
indexes = [
{
'name': 'flat_index',
'column': 'embeddings',
'type': 'flat',
'params': {"dims": 1536, "metric": "L2"},
}
]
# Create the KDB.AI table
table = database.create_table("rag_langchain", schema=rag_schema, indexes=indexes)- Embedding: The data, now chunked and in natural language format, is converted into machine-readable form using an embedding model that transforms word into numerical codes reflecting their meaning and relationships. These “word embeddings” are stored as vectors in a KDB.AI. This approach enhances efficiency and accuracy by compressing data for optimized storage and retrieval, enabling effective similarity searches through methods like cosine similarity and Euclidean distance, and augmenting LLM generation and relevance with semantically contextual information.
- User Prompt & Embedding: The user now enters a prompt referencing the information that has been stored in the vector database. This prompt is also embedded by the same model that embedded the ingested documentation. Now we have a vector embedding of the prompt.
- Similarity Search: The prompt vector embedding is compared to the vectors within the vector store via similarity algorithms like cosine similarity or Euclidean similarity. The search will reveal which vectors in the vector database are most relevant to the prompt.
- Generation with LLM: The LLM is queried with the user prompt, relevant chunks of data found from the similarity search, and any conversational history. With all this information the LLM has the context to respond with information based on our dataset.
This naïve RAG methodology is fast and efficient but could provide inaccurate results if the user is prompting the system on topics that are not held within the documentation. This offers some ‘safety’ from having unrestricted access to the foundation model’s entire training set but is quite restrictive in the fact that users must only query on specific topics.
Agent Assisted RAG
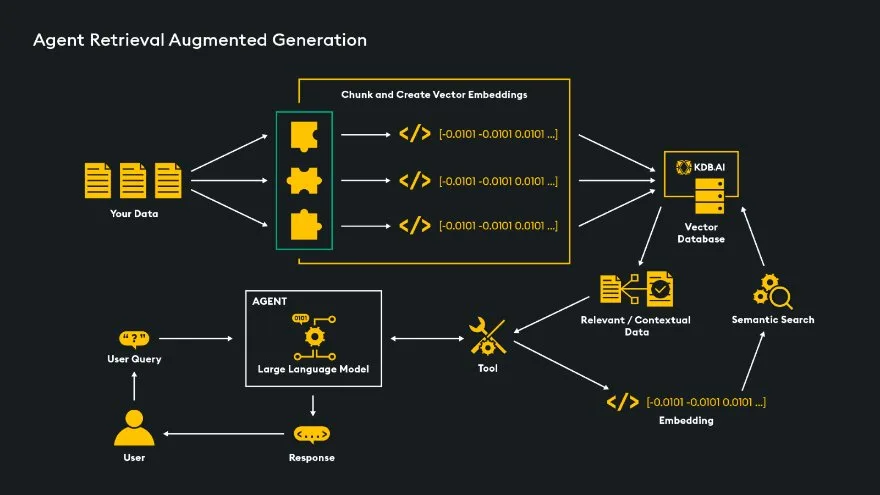
Agent RAG uses LLM powered decision making agents to determine the best next steps to generate a satisfactory response based on a user’s input query. Agents have access to various ‘tools’ that perform specific tasks and enhance the LLM’s functionality, with the agent deciding which tools to use and when.
A tool is a function or method that an agent can call to complete a task. Tools include calculators, code executers, search engines, document search tool, SQL query engines and custom tool built for specific functionality. A custom RAG tool can be added to an agent’s arsenal and offers a solution to the problem of Naïve RAG. Users can prompt the LLM on many topics, and the agent will decide when to execute the RAG pipeline custom tool, another tool, or to just sent the query directly to the LLM.
Here is a list of available agent tools in LangChain.
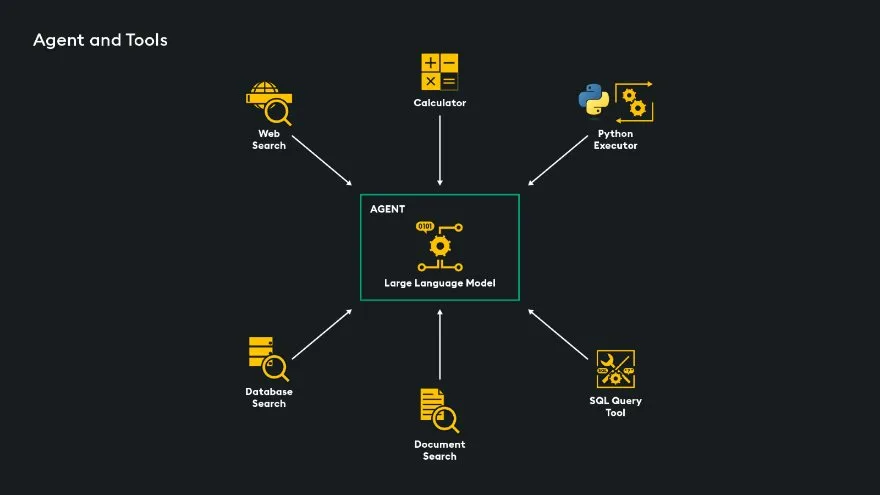
The agent approach is powerful but slower and more expensive. It involves at least two LLM calls: once to determine the next step based on the input query and once to generate the final response. More calls may be needed for multistep tasks, increasing costs and time. However, the availability of prebuilt tools, like calculators, can make it worthwhile for certain use cases.
Guardrails RAG
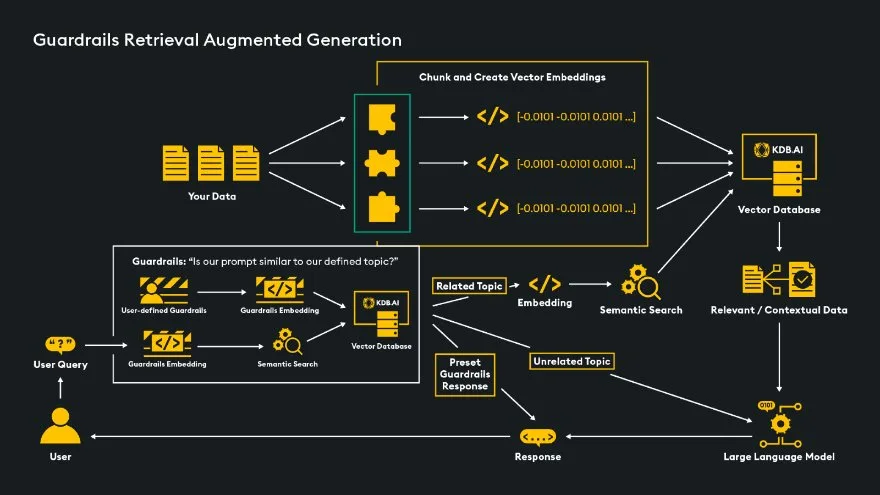
The Guardrails RAG method, as exemplified by Nvidia NeMo’s Guardrails, streamlines conversation flow by allowing the definition of specific topics and custom next steps without relying on a large language model, thereby increasing speed and cost-effectiveness. Configuration is done through a .yaml file specifying the engine, LLM (for generating a response, not deciding next steps), and conversation flow, including “Ask” (defining topics and example phrases), “Answer” (specifying responses), and “Flow” (outlining conversational progression). Semantic similarity checks ensure that prompts are related to specified topics, improving accuracy and efficiency by limiting RAG use to relevant prompts. Despite the additional setup required, Guardrails provide a safer, more consistent solution, particularly for customer-facing applications using LLMs. There are several paths we can take with Guardrails:
- Custom & Consistent Responses: If the user prompts about sensitive topics like politics or finances, we can set up an automatic response to prevent the prompt from being sent to the RAG pipeline or LLM. Similarly, for consistent introductions, we can specify this conversational flow as a guardrail.
- Query the LLM: When the user prompt does not fall into any of our specified topics, we could choose to send the query to the LLM and have the LLM generate a response for the user.
- RAG: If the user prompt matches a specific topic that we have set in our guardrails configuration, for example data science, we can have this prompt sent through the RAG pipeline to find relevant data in our vector database.
Knowledge Graph Aided RAG
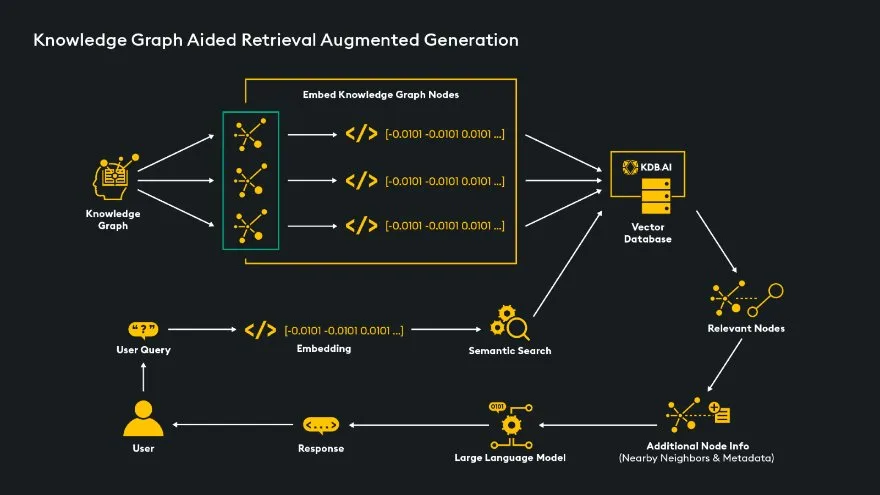
Knowledge graph (KG) aided RAG enhances LLM context by adding information from a knowledge graph to the relevant data found in vector database similarity searches. Unlike Naïve RAG, which ingests and embeds documents, this method ingests and embeds knowledge graph nodes. After the similarity search, relevant nodes are returned. The key advantage of KG aided RAG is its ability to traverse from these nodes to their neighboring nodes, providing the LLM with maximum context by including both relevant and neighboring nodes.
LangChain has also added capability called Cypher Search that translates natural language queries into graph query languages so information can be extracted from a KG directly.
Time-Based RAG
The goal of time-based RAG is to provide users with the most relevant results from a similarity search by using dates and times as a search filter. To do this, we can add dates and times as a metadata component on our ingested data – which will give the ability to ask time-based questions about our data. Some examples of temporal metadata are a creation date, publishing date, or last updated data.
Use-cases include searching within a time range, before or after a certain date, finding the most recent embeddings, for time-series data, and to give an LLM a sense of time so we can ask time-based questions about our data. We can specifically retrieve embedded data by specifying a timeframe, or if we give an LLM our metadata schema, it can infer upon timeframe depending on the query.
rag_schema = [
{"name": "id", "type": "str"},
{"name": "date", "type": "datetime64[ns]"}
{"name": "text", "type": "bytes"},
{
"name": "embeddings",
"type": "float64s",
},
]Another approach to identifying the most relevant data is to assign an importance weight based on time, with the weight decreasing as time progresses according to a set decay rate. Consequently, newer data will have a higher weight than older data.
Time-based retrieval is very relevant to use-cases where data is constantly changing and being updated, such as time series use-cases, news articles, stock prices, social media posts, and weather information.
RAG Improvements & Optimization:
Generate multiple queries: there is the possibility that generating queries based on the users input prompt might yield better results. Sometimes the LLM can generate a better prompt than the user could have. LangChain has a retriever called “MultiQueryRetriever” that can generate similar queries to the original input query and then retrieve all relevant information from the vector database based on the original query and the generated similar queries.
question = "What are key capabilities of the data science tool Pandas?"
retriever_from_llm = MultiQueryRetriever.from_llm(
retriever=vectordb.as_retriever(), llm = llm
)
docs = retriever_from_llm.get_relevant_documents(query=question)Retrieval Methods: When identifying the relevant information during similarity search between data in the vector database and the user query, there are methods we can use to improve the accuracy and speed of retrieval.
Chunk Decoupling: When retrieving from a vector database, we can treat the retrieval step of the pipeline differently than the generation step. Differentiating between what we embed and perform similarity search on within the vector database, and what we provide to the LLM for relevant context during synthesis, can offer advantages.
- Document Summary: Each document is summarized using an LLM, embedded, and stored in a vector database. The user queries the system, and the highly relevant summaries are retrieved. These summaries link to chunks associated with this document and those chunks are provided to the LLM for generation. This ensures we only get chunks from relevant documents, not chunks from irrelevant documents. See code example from LlamaIndex.
- Sentence Text Windows: Each sentence is chunked, embedded, and stored in the vector database. Upon similarity search, relevant sentences and a larger surrounding text window supply extra context are provided to the LLM for generation. See code example from LlamaIndex.
- Parent Document Retriever: This method involves chunking original documents, storing their vector embeddings in a database, and linking relevant chunks back to their parent documents during similarity search. This ensures a granular search during retrieval, and detailed context from the parent document for the LLM during generation. See LangChain code example.
Structured Retrieval: As the number of documents increases, standard RAG starts to have issues with retrieving the most relevant information. The addition of structured information, like metadata tags, can increase the relevancy of retrieved information.
- Metadata Filters & Auto-Retrieval: Each document ingested into the vector database is tagged with metadata, embedded, and stored. User queries are automatically tagged with metadata using a method called Auto-Retrieval from LlamaIndex or with LangChain’s SelfQueryRetriever. A pre-processing step filters the data in the vector database by metadata, ensuring only matching documents and chunks are returned. This method avoids similarity searches on unrelated documents or chunks. See code example from LlamaIndex.
- Document Hierarchy: The original document is chunked into raw chunks that are tagged with relevant metadata, then the original document is summarized, embedded, and stored in a vector database. The query is tagged and embedded, and the most similar document summaries are retrieved. The document summaries are linked to their raw and tagged original chunks and the chunks with matching tags are returned to the LLM for generation.
Reranking: In similarity search, the embedded prompt and data in the vector database are compared to find the most relevant chunks. However, embedding can result in information loss, so vector search may not always yield the best top-k matches. To improve accuracy, we can use a reranker, a transformer-based algorithm that provides better similarity computation. By processing a larger subset of data retrieved from vector search and the user prompt, the reranker identifies the true best top-k matches for the LLM’s generation.
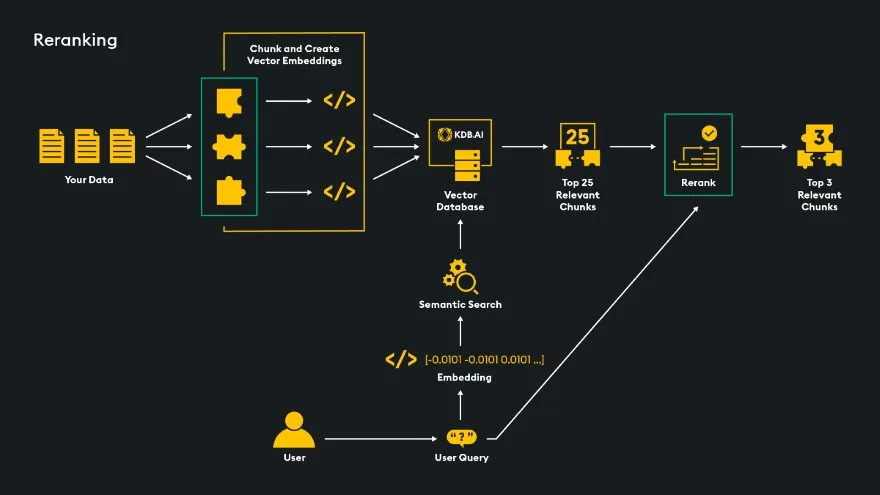
In this example reranking architecture, our goal is to provide the top 3 relevant matches to an LLM for generation. We have the initial vector database similarity search return a substantial set of top-k most relevant matches such as the top-25. The reranker then compares the user’s prompt to the top 25 retrieved chunks and returns the top 3 relevant matches. We do not send our entire dataset to the reranker because it is a transformer model that takes longer to process similarity searches, so we take advantage of the fast vector search to return a large subset of relevant chunks.
Recursive Retrieval: A method of retrieval introduced by LlamaIndex to recursively retrieve information from different and hierarchical documents. A recursive retriever can direct retrieval from separate sources, including multiple documents, vector databases, summary indexes, and specialized agents/tools.
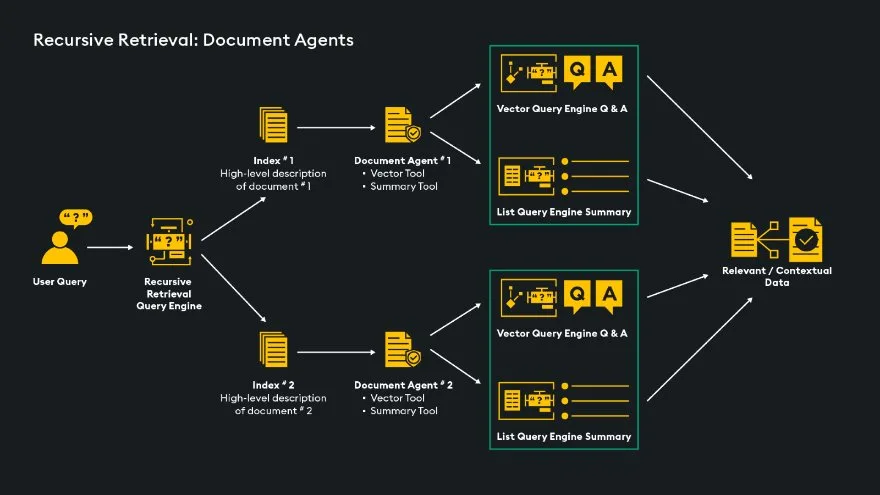
This architecture example of using “RecursiveRetriever” from LlamaIndex shows how a single document can be searched from a pool of multiple documents depending on the input query. In this case, there are two possible documents, and the recursive retriever directs the query to whichever document is most appropriate. It identifies the best option using index nodes, each containing a document’s brief description. Once a path is chosen, the document’s agent selects the optimal search method (vector or summary) based on the user’s query. Finally, relevant information is extracted and sent to an LLM. See a comparison of Auto-Retrieval and Recursive Retrieval here.
Wrapping Up
In this article the topics of Retrieval Augmented Generation, RAG approaches, and RAG Optimization methods were introduced and explained. RAG is a powerful methodology that will enable a LLM to answer questions about your data. The vector database is a central element to RAG workflows and powers the retrieval of relevant data, KDB.AI offers a free and easy way to get started. Check out the Retrieval Augmented Generation notebook today to get started with building your own RAG pipeline!
References & Learn More: